Ĉapitro 14 - Laborante kun CSV dosierojn kaj JSON Datumoj



Subtenu la Aŭtoro: Aĉeti la libron sur Amazono aŭ
la libro / ebook pakaĵo rekte Neniu amelo Gazetaro .

Legi la aŭtora aliaj liberaj Python libroj:



Laborante kun CSV dosierojn kaj JSON Datumoj
En ĉapitro 13 , vi lernis kiel ĉerpi tekston de PDF kaj Word dokumentoj. Tiuj dosieroj estas en duuma formato, kiu postulis specialan Python moduloj konsenti liajn datumojn. CSV kaj JSON dosierojn, aliflanke, estas nur teksto dosierojn. Vi povas vidi ilin en tekstoredaktilo, kiel sencela la dosiero redaktoro. Sed Python ankaŭ venas kun la speciala
csv kaj json moduloj, ĉiu havigi funkciojn por helpi vin labori kun tiuj formatoj.
CSV signifas "komo-apartigita valorojn" kaj CSV dosieroj simpligita kalkultabelojn stokita kiel teksto dosierojn. Python
csv modulo faciligas analizi CSV dosierojn.
JSON (prononcita "JAY-segita" aŭ "Jason" -ĝi ne gravas kiom pro ajna
vojo popolo diros vi prononci ĝin malĝusta) estas formato kiu stokas
informon Javascript fontkodo en fonta teksto dosierojn.
(JSON estas mallonga por JavaScript Objekto Skribmaniero.) Vi ne
bezonas scii la JavaScript programlingvo uzi JSON dosierojn, sed la JSON
formato estas utila por scii ĉar ĝi estas uzata en multaj aplikoj
retejo.
La CSV Modulo
Ĉiu linio en CSV-dosiero reprezentas vicon en la kalkultabelo, kaj komoj apartigas la ĉelojn en la vico. Ekzemple, la kalkultabelo example.xlsx de http://nostarch.com/automatestuff/ aspektus tiel en CSV-dosiero:
4/5/2015 13: 34, Pomoj, 73 4/5/2015 3: 41, ĉerizoj, 85 4/6/2015 12: 46, Piroj, 14 4/8/2015 8: 59, Oranĝoj, 52 4/10/2015 2: 07, Pomoj, 152 4/10/2015 18: 10, Bananoj, 23 4/10/2015 2: 40, Fragoj, 98
Mi uzos tiun dosieron por tiu ĉapitro la interaga ŝelo ekzemploj. Vi povas elŝuti example.csv de http://nostarch.com/automatestuff/ aŭ eniri la tekston en tekstredaktilo kaj savu gxin kiel example.csv.
CSV dosieroj estas simpla, mankas multaj el la karakterizaĵoj de Excel kalkultabelo. Ekzemple, CSV dosierojn
- Ne havas tipoj por iliaj valoroj-ĉio estas ĉeno
- Ne havas agordon por tiparo grandeco aŭ koloro
- Ne havas multoblajn laborfolioj
- Ne eblas specifi ĉelo larĝoj kaj altoj
- Ne havas kunfandita ĉeloj
- Ne havas bildojn aŭ lertaj enigita en ili
La avantaĝo de CSV dosierojn estas simpleco.
CSV dosieroj vaste apogita de multaj tipoj de programoj, videblas en
teksto redaktiloj (inkluzive sencela la dosiero redaktoro), kaj estas
simpla maniero por reprezenti kalkultabelo datumoj. La CSV formato estas precize kiel anoncita: Estas nur teksta dosiero de komo-apartigita valorojn.
Ekde CSV dosierojn jxus tekstdosieroj, vi povus esti tentita por legi
ilin en kiel linio kaj tiam procesi ke ŝnuro uzante la teknikoj vi
lernis en Ĉapitro 8 . Ekzemple, ekde ĉiu ĉelo en CSV-dosiero estas apartigitaj per komo, eble vi povus simple nomi la
split() metodo sur ĉiu linio de teksto por ricevi la valorojn. Sed ne ĉiu komo en CSV-dosiero reprezentas la limon inter du ĉeloj. CSV dosierojn ankaŭ havas sian propran aron de eskapo karakteroj permesi komoj kaj aliaj karakteroj por esti inkludita kiel parto de la valoroj. La split() metodo ne manipuli tiujn eskapo karakteroj. Pro tiuj potencialaj enfaliloj, vi devus ĉiam uzi la csv modulo por legi kaj skribi CSV dosierojn. leganto Objektoj
Legi datumojn de CSV-dosiero kun la
csv modulo, vi devas krei Reader objekto. A Reader objekto permesas persisti super linioj en la CSV-dosiero. Eniri la sekva en la interaga ŝelo, kun example.csv en la nuna labordosierujon: ❶ >>> import CSV ❷ >>> exampleFile = malfermita ( 'example.csv') ❸ >>> exampleReader = csv.reader (exampleFile) ❹ >>> exampleData = listo (exampleReader) ❹ >>> exampleData [[ '4/5/2015 13:34', 'Apples', '73'], [ '4/5/2015 3:41', 'ĉerizoj', '85'], [ '4/6/2015 12:46', 'Piroj', '14'], [ '4/8/2015 8:59', 'oranĝoj', '52'], [ '4/10/2015 2:07', 'Apples', '152'], [ '4/10/2015 18:10', 'Ringoj', '23'], [ '4/10/2015 2:40', 'Fragoj', '98']]
La
csv modulo venas kun Python, do ni povas importi ĝin ❶ sen devi instali ĝin unue.
Legi CSV -dosiero kun la
csv modulo, unue malfermu ĝin uzante la open() funkcio ❷, ĝuste kiel vi farus ajnan alian tekstdosiero. Sed anstataŭ vokanta la read() aŭ readlines() metodon sur la File objekto kiu open() redonas, pasi ĝin al la csv.reader() funkcio ❸. Tio resendas Reader objekto por vi uzi. Notu ke vi ne pasas dosiernomo ĉeno rekte al la csv.reader() funkcio.
La plej rekta maniero aliri la valoroj en la
Reader objekto devas konverti ĝin al ebenaĵo Python listo pasante al list() ❹. Uzante list() sur ĉi Reader objekto resendas liston de listoj, kiu povas stoki en variablo kiel exampleData . Enirante exampleData en la ŝelo montras la lerta de lertaj ❺.
Nun ke vi havas la CSVa dosiero kiel listo de listoj, vi povas aliri la valoro je aparta vico kaj kolumno kun la esprimo
exampleData[row][col] , kie row estas la indekso de unu el la lertaj en exampleData kaj col estas la indekso de la elemento vi volas el tiu listo. Eniri la sekva en la interaga konko: >>> ExampleData [0] [0] '4/5/2015 13:34' >>> ExampleData [0] [1] 'Apples' >>> ExampleData [0] [2] '73' >>> ExampleData [1] [1] 'Ĉerizoj' >>> ExampleData [6] [1] 'Fragoj'
exampleData[0][0] iras en la unuan liston kaj donas al ni la unua kordo, exampleData[0][2] iras en la unuan liston kaj donas al ni la tria ŝnuro, kaj tiel plu. Legante Datumoj de Leganto objektoj en por Loop
Cxar granda CSV dosierojn, vi volas uzi la
Reader objekto en for buklo. Tio evitas ŝarĝi la tutan dosieron en memoro samtempe. Ekzemple, tajpu la sekvajn en la interaga konko: >>> Import CSV >>> ExampleFile = malfermita ( 'example.csv') >>> ExampleReader = csv.reader (exampleFile) >>> Por vico en exampleReader: print ( 'Row #' + str (exampleReader.line_num) + '' + str (vico)) Vico # 1 [ '4/5/2015 13:34', 'Apples', '73'] Vico # 2 [ '4/5/2015 3:41', 'ĉerizoj', '85'] Vico # 3 [ '4/6/2015 12:46', 'Piroj', '14'] Vico # 4 [ '4/8/2015 8:59', 'oranĝoj', '52'] Vico # 5 [ '4/10/2015 2:07', 'Apples', '152'] Vico # 6 [ '4/10/2015 18:10', 'Ringoj', '23'] Vico # 7 [ '4/10/2015 2:40', 'Fragoj', '98']
Post vi importi la
csv modulo kaj fari Reader objekto de la CSV-dosiero, vi povas buklo tra la vicoj en la Reader objekto. Ĉiu vico estas listo de valoroj, kun ĉiu valoro reprezentanta ĉelo.
La
print() funkcion alvoko presas la numeron de la nuna vico kaj la enhavo de la vico. Akiri la vico nombro, uzi la Reader objekto line_num variablo, kiu entenas la nombro de la aktuala linio.
La
Reader objekto povas esti ripeta GIF super nur unufoje. Releer la CSV-dosiero, nomu csv.reader krei Reader objekto. verkisto Objektoj
A
Writer objekto permesas skribi datumojn al CSV-dosiero. Krei Writer objekto, oni uzas la csv.writer() funkcio. Eniri la sekva en la interaga konko: >>> Import CSV ❶ >>> outputFile = malfermita ( 'output.csv', 'w', lino = '') ❷ >>> outputWriter = csv.writer (outputFile) >>> OutputWriter.writerow ([ 'spamado', 'ovojn', 'lardo', 'ham']) 21 >>> OutputWriter.writerow ([ 'Saluton, mondo!', 'Ovojn', 'lardo', 'ham']) 32 >>> OutputWriter.writerow ([1, 2, 3,141592, 4]) 16 >>> OutputFile.close ()
Unue, nomu
open() kaj fordoni 'w' malfermi dosieron en registran reĝimo ❶. Tio kreos la objekto vi povas tiam pasas al csv.writer() ❷ krei Writer objekto.
En Windows, vi ankaŭ bezonos pasi malplenan ĉenon por la
open() funkcio de newline ŝlosilvorto argumento. Por teknikaj kialoj preter la kadro de tiu libro, se vi forgesu agordi la newline argumenton, la vicoj en output.csv estos duobla-spacitaj, kiel montrita en Figuro 14-1 . 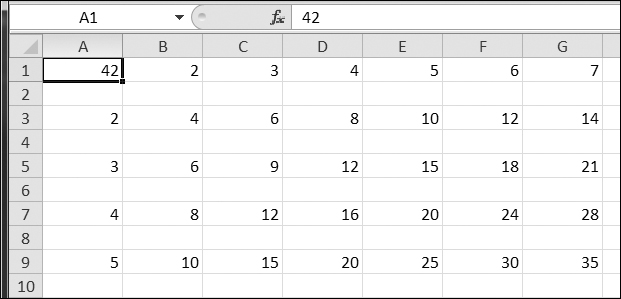
Figuro 14-1. Se vi forgesos la
newline='' ŝlosilvorto argumento en open() , la CSV-dosiero estos duobla-spacitaj.
La
writerow() metodo por Writer objektoj prenas liston argumento. Ĉiu valoro en la listo estas metita en lia propra ĉelo en la eligo CSVa dosiero. La reveno valoro de writerow() estas la nombro de karakteroj skribitaj al la dosiero por ke vico (inkluzive linion karakteroj).
Tiu kodo produktas output.csv dosieron kiu similas tiun:
spamado, ovojn, lardon, ŝinkon "Saluton, mondo!", Ovojn, lardon, ŝinkon 1,2,3.141592,4
Rimarku kiel la
Writer objekto aŭtomate eskapas la komo en la valoro 'Hello, world!' Kun citiloj en la CSV-dosiero. La csv modulo savas vin el devi manipuli tiujn specialajn kazojn mem. La delimitador kaj lineterminator Temo Argumentoj
Diru vi volas disigi ĉelojn kun langeto karaktero anstataŭ komo kaj vi volas la vicoj esti duobla-spacitaj. Vi povus eniri iun kiel la sekva en la interaga konko:
>>> Import CSV >>> CsvFile = malfermita ( 'example.tsv', 'w', lino = '') ❶ >>> csvWriter = csv.writer (csvFile, delimitador = '\ t', lineterminator = '\ n \ n') >>> CsvWriter.writerow ([ 'pomojn', 'oranĝoj', 'vinberoj']) 24 >>> CsvWriter.writerow ([ovojn ',' lardo ',' ham ']) 17 >>> CsvWriter.writerow ([ 'spamado', 'spamado', 'spamado', 'spamado', 'spamado', 'spamado']) 32 >>> CsvFile.close ()
Ŝanĝas la delimitador kaj linio finilo karakteroj en via dosiero. La delimitador estas la karaktero kiu aperas inter ĉeloj en vico. Defaŭlte, la delimitador por CSV-dosiero estas komo. La linio finilo estas la karaktero kiu venas ĉe la fino de vico. Defaŭlte, la linio finilo estas lino. Vi povas ŝanĝi gravulojn al malsamaj valoroj uzante la
delimiter kaj lineterminator ŝlosilvorto argumentojn kun csv.writer() .
Pasante
delimeter='\t' kaj lineterminator='\n\n' ❶ ŝanĝas la karakteron inter ĉeloj al langeto kaj la karaktero inter vicoj al du linifinojn. Ni tiam nomita writerow() tri fojojn doni nin tri vicoj.
Tio produktas Dosiero nomita example.tsv kun jenaj enhavoj:
pomoj oranĝoj vinberoj ovojn lardo ŝinko spamado spamado spamado spamado spamado spamon
Nun niaj ĉeloj estas disigitaj de langetoj, ni uzas la dosiersufikso .tsv, por tab-apartigitaj valoroj.
Projekto: Forigado la Kapa el CSV dosieroj
Diru vi havas la enuiga tasko de forigado de la unua linio de kelkcent CSV dosierojn. Eble vi estos nutrante ilin en aŭtomata procezo kiu postulas nur la datumoj ne la titolaj ĉe la supro de la kolonoj. Vi povus malfermi ĉiun dosieron en Excel, forigu la unua vico, kaj resave la dosiero-sed kiu portus horojn. Ni skribi programon por fari ĝin anstataŭe.
La programo devos malfermi ĉiun dosieron kun la CSV
etendo en la nuna laboranta dosierujo, legis la enhavon de la
CSV-dosiero, kaj reverki la enhavon sen la unua vico al dosiero de la
sama nomo. Ĉi anstataŭos la malnovan enhavon de la CSVa dosiero kun la nova, senkapa enhavo.
noto
Kiel
ĉiam, kiam vi skribas programon kiu modifas dosierojn, nepre subteni la
dosierojn, unua ĉiaokaze via programo ne funkcias kiel vi atendas ĝin. Vi ne volas akcidente viŝi viajn originalajn dosierojn.
Je alta nivelo, la programo devas fari la sekvajn:
- Trovu ĉiujn CSV dosierojn en la nuna labordosierujon.
- Legi en la plena enhavo de ĉiu dosiero.
- Skribi la enhavon, saltante la unua linio, al nova CSVa dosiero.Ĉe la kodon nivelo, tiu signifas la programo devos fari la sekvan:
- Buklo super listo de dosieroj el
os.listdir(), saltante la ne-CSV dosierojn. - Krei CSV
Readercelon kaj legi en la enhavon de la dosiero, uzante laline_numatributo elkompreni kion linio salti. - Krei CSV
Writercelon kaj skribi la legado en datumoj al la nova dosiero.
Por tiu projekto, malfermi novan dosieron redaktanto fenestro kaj savi ĝin kiel removeCsvHeader.py.
Paŝo 1: Loop Tra Ĉiu CSV Dosiero
La unua afero via programo bezonas fari estas buklo super liston de ĉiuj CSV dosiernomojn por la nuna labordosierujon. Fari vian removeCsvHeader.py aspektas tiel:
#! python3 # RemoveCsvHeader.py - Forigas la kaplinio de ĉiuj CSV dosierojn en la nuna # Laboranta dosierujo. importado CSV, os os.makedirs ( 'headerRemoved', exist_ok = Vera) # Loop tra ĉiu dosiero en la aktuala labordosierujon. por csvFilename en os.listdir ( '.'): se ne csvFilename.endswith ( '. CSV): ❶ daŭrigi # salti ne- CSV dosierojn print ( 'Forigado kaplinio de' + csvFilename + '...') # TODO: Legu la CSVa dosiero en (saltante unua vico). # TODO: Skribu la CSV-dosiero.
La
os.makedirs() alvoko kreos headerRemoved dosierujo kie ĉiuj senkapa CSV dosieroj estos skribita. A for buklo sur os.listdir('.') Akiras vin partway tie, sed ĝi estos buklo super ĉiuj
dosieroj en la laboranta dosierujo, do vi bezonos aldoni iun kodon ĉe
la komenco de la ciklo, kiu saltas dosiernomoj kiuj don ' t fini kun .csv . La continue deklaro ❶ faras la for buklo movo sur al la sekvanta dosiernomo kiam temas tra ne-CSVa dosiero.
Nur tiel ekzistas iuj eligo kiel la programo funkcias, presi mesaĝon dirante ke CSV -dosiero la programo laboras en. Tiam, aldoni kelkajn
TODO komentoj por kio la resto de la programo devus fari. Paŝo 2: Legi la CSV Dosiero
La programo ne forigi la unuan linion de la CSVa dosiero. Prefere, ĝi kreas novan kopion de la CSVa dosiero sen la unua linio. Ekde la kopion de dosiernomo estas la sama kiel la originala dosiernomo, la kopion anstataŭigos la originalaj.
La programo bezonos manieron spuri ĉu nuntempe looping sur la unua vico. Aldonu la jenan al removeCsvHeader.py.
#! python3 # RemoveCsvHeader.py - Forigas la kaplinio de ĉiuj CSV dosierojn en la nuna # Laboranta dosierujo. --snip-- # Legi la CSVa dosiero en (saltante unua vico). csvRows = [] csvFileObj = malfermita (csvFilename) readerObj = csv.reader (csvFileObj) por vico en readerObj: se readerObj.line_num == 1: daŭrigi # salti unua vico csvRows.append (vico) csvFileObj.close () # TODO: Skribu la CSV-dosiero.
La
Reader objekto line_num atributo povas uzi por determini kiu linio en la CSV-dosieron estas nuntempe leganta. Alia for buklo volo buklo super la vicoj revenis de la CSVa Reader celon, kaj ĉiuj vicoj sed la unuaj estos aldonata csvRows .
Kiel la
for buklo ripetas super ĉiu vico, la kodo ĉekojn ĉu readerObj.line_num enkadriĝas al 1 . Se jes, ĝi ekzekutas continue movi sur al la sekvanta vico sen appending ĝin csvRows . Por ĉiu vico poste, la kondiĉo estos ĉiam esti False , kaj la vico estos aldonata csvRows . Paŝo 3: Skribu El la CSV Dosiero Sen la Unua Vico
Nun ke
csvRows enhavas ĉiujn vicojn sed la unua vico, la listo devas esti skribita al CSV-dosiero en la headerRemoved dosierujo. Aldonu la sekvan al removeCsvHeader.py: #! python3 # RemoveCsvHeader.py - Forigas la kaplinio de ĉiuj CSV dosierojn en la nuna # Laboranta dosierujo. --snip-- # Loop tra ĉiu dosiero en la aktuala labordosierujon. ❶ por csvFilename en os.listdir ( '.'): se ne csvFilename.endswith ( '. CSV): daŭrigi # salti ne- CSV dosierojn --snip-- # Skribu la CSV-dosiero. csvFileObj = malfermita (os.path.join ( 'headerRemoved', csvFilename), 'w', lino = '') csvWriter = csv.writer (csvFileObj) por vico en csvRows: csvWriter.writerow (vico) csvFileObj.close ()
La CSV
Writer objekto skribos la listo al CSV-dosiero en headerRemoved uzante csvFilename (kiun ni uzis en la CSV leganto). Ĉi anstataŭigos la originalan dosieron.
Unufoje ni kreas la
Writer objekton, ni buklo super la Alsublistige stokitaj en csvRows kaj skribi ĉiu subliston al la dosiero.
Post la kodo estas ekzekutita, la ekstera
for buklo ❶ volo buklo al la sekva dosiernomo de os.listdir('.') . Kiam tiu buklo estas finita, la programo estos kompleta.
Testi vian programon, elŝutu removeCsvHeader.zip de http://nostarch.com/automatestuff/ kaj maldensigi ĝin al dosierujo. Kuri la removeCsvHeader.py programo en tiu dosierujo. La eligo aspektos tiel ĉi:
Forigado kaplinio de NAICS_data_1048.csv ... Forigado kaplinio de NAICS_data_1218.csv ... --snip-- Forigado kaplinio de NAICS_data_9834.csv ... Forigado kaplinio de NAICS_data_9986.csv ...
Tiu programo devus presi dosiernomo ĉiufoje ĝi filmas la unua linio de CSV-dosiero.
Ideoj por Similaj Programoj
La programoj kiujn vi povus skribi por CSV dosieroj similaj al la
specoj vi povus skribi por Excel dosierojn, ĉar ili estas ambaŭ
kalkultabelo dosierojn. Vi povus skribi programojn por fari la sekvajn:
- Kompari datumojn inter malsamaj vicoj en CSV-dosiero aŭ inter multoblaj CSV dosierojn.
- Kopiu specifaj datumoj de CSV-dosiero al Excel-dosiero, aŭ inverse.
- Kontroli por nevalida datumoj aŭ formatado eraroj en CSV dosierojn kaj alarmi la uzanton tiuj eraroj.
- Legi datumojn de CSV dosiero enigo por via Python programoj.
JSON kaj APIs
JavaScript Objekto Skribmaniero estas populara maniero por formati datumojn kiel ununura facile komprenebla ŝnuro. JSON estas la denaska maniero ke Ĝavoskripto skribi ilian datumstrukturoj kaj kutime similas kion Python
pprint() funkcio produktus. Vi ne bezonas scii JavaScript por labori kun JSON-formatita datumoj.
Jen ekzemplo de datumoj formatita kiel JSON:
{ "Nomo": "Zophie", "isCat": vera, "MiceCaught" 0 "napsTaken": 37.5, "FelineIQ" null}
JSON estas utile scii, ĉar multaj retejoj proponas JSON enhavo kiel maniero por programoj por interagi kun la retejo. Ĉi tio konas kiel disponigado apliko programado interfaco (API). Alirante API estas la sama kiel aliri ajna alia retpaĝo per URL. La diferenco estas ke la datumoj revenis de API estas formatita (kun JSON, ekzemple) por maŝinoj; API ne estas facilaj por homoj por legi.
Multaj retejoj faras siajn datumojn haveblaj en JSON formato.
Facebook, Twitter, Yahoo, Google, Tumblr, Vikipedio, Flickr, Data.gov,
Reddit, IMDb, Rotten Tomatoes, LinkedIn, kaj multaj aliaj popularaj ejoj
proponas API por programoj uzi. Iuj de ĉi tiuj lokoj postulas registron, kiu estas preskaŭ ĉiam libera.
Vi devos trovi dokumentado por kio URLoj via programo bezonas peti por
akiri la datumojn vi volas, tiel kiel la ĝenerala formato de la JSON
datumoj strukturoj kiuj revenis. Ĉi dokumentado estu provizita per nenial retejon proponas la API; se ili havas "Programistoj" paĝo, serĉi la dokumentado tie.
Uzante API, vi povus skribi programojn kiuj faras la sekvajn:
- Skrapadi krudaj datenoj de retejoj. (Aliri API estas ofte pli oportuna ol elŝutanta retpaĝojn kaj sintaksa analizo HTML kun Bela Supo.)
- Aŭtomate elŝuti novajn afiŝojn el iu el viaj sociaj reto kontoj kaj sendi ilin al alia konto. Ekzemple, vi povus preni viajn Tumblr afiŝojn kaj sendi ilin al Facebook.
- Krei "filmo enciklopedio" por via persona filmo kolekto tirante datumoj de IMDb, Rotten Tomatoes, kaj Vikipedio kaj metante ĝin en ununura tekstdosiero sur via komputilo.
Vi povas vidi iujn ekzemplojn de JSON API en la rimedoj je http://nostarch.com/automatestuff/ .
La JSON Modulo
Python
json modulo manipulas ĉiujn detalojn de tradukado inter ŝnuro kun JSON datumoj kaj python valoroj por la json.loads() kaj json.dumps() funkcioj. JSON ne povas stoki ĉiun tipon de Python valoro. Ĝi povas enhavi valorojn de la Vikimedia datumtipoj: kordoj, entjeroj, flosas, Booleans, listoj, vortaroj, kaj NoneType . JSON ne reprezentas Python-specifaj celoj, kiel File objektoj, CSV Reader aŭ Writer objektoj, Regex objektoj, aŭ seleno WebElement objektoj. Legante JSON kun la ŝarĝoj () Funkcio
Traduki kordo enhavanta JSON datumoj en Python valoro, pasi ĝin al la
json.loads() funkcio. (La nomo signifas "ŝarĝo ŝnuro," ne "ŝarĝoj.") Enmetu la sekva en la interaga konko: >>> StringOfJsonData = '{ "nomo": "Zophie", "isCat": vera, "miceCaught": 0, "felineIQ" null} ' >>> Import JSON >>> JsonDataAsPythonValue = json.loads (stringOfJsonData) >>> jsonDataAsPythonValue { 'IsCat': Vera: miceCaught '0,' nomo ':' Zophie ',' felineIQ ': Neniu}
Post vi importi la
json modulo, vi povas voki loads() kaj pasas ĝin ĉenon de JSON datumoj. Notu ke JSON kordoj ĉiam uzi citiloj. Ĝi revenos ke datumoj kiel Python vortaro. Python vortaroj ne ordigita, do la ŝlosilo valoro paroj povas aperi en malsama ordo kiam vi presi jsonDataAsPythonValue . Skribi JSON kun la vertederos () Funkcio
La
json.dumps() funkcio (kiu signifas "dump ŝnuro," ne "rubejojn") tradukos Python valoro en ŝnuro de JSON-formatita datumoj. Eniri la sekva en la interaga konko: >>> PythonValue = { 'isCat': Vera: miceCaught '0,' nomo ':' Zophie ', 'felineIQ': Neniu} >>> Import JSON >>> StringOfJsonData = json.dumps (pythonValue) >>> stringOfJsonData '{ "IsCat": vera, "felineIQ" null "miceCaught" 0 "nomo": "Zophie"}'
La valoro povas esti nur unu el la sekvaj bazaj Python datumtipoj: vortaro, listo, entjero, kaleŝego, kordoj, Bulea, aŭ
None . Projekto: Elprenante Nuna vetero Datumoj
Kontrolanta la vetero ŝajnas sufiĉe banalaj: Malfermu vian retumilon,
klaku la stango, tajpi la URL vetera retejo (aŭ serĉi kaj alklaki la
ligilon), atendas la paĝo ŝarĝi, rigardi preter ĉiuj anoncoj, kaj tiel
plu.
Fakte, ekzistas amaso da enuiga paŝoj vi povus salti se vi havis
programon kiu elŝutis la veterprognozo por la sekvantaj malabundaj tagoj
kaj presitaj kiel kompleta teksto. Ĉi programo uzas la
requests modulo de Ĉapitro 11 elŝuti datumojn de la retejo.
Totala, la programo faras la sekvajn:
- Legas la petita loko de la komandlinio.
- Elŝutoj JSON meteorológica de OpenWeatherMap.org.
- Konvertas la kordo de JSON datumoj al Python datumstrukturo.
- Presas la vetero hodiaŭ kaj la venontaj du tagoj.Tial la kodo devas fari la sekvajn:
- Aliĝi kordoj en
sys.argvakiri la ubicación. - Voku
requests.get()elŝuti la meteorológica. - Voku
json.loads()por konverti la JSON datumoj al Python datumstrukturo. - Presi la veterprognozo.
Por tiu projekto, malfermi novan dosieron redaktanto fenestro kaj savi ĝin kiel quickWeather.py.
Paŝo 1: Akiri Situo de la Komando Linio Argumento
La enigo por tiu programo venos de la komandlinio. Fari quickWeather.py aspektas tiel:
#! python3 # QuickWeather.py - Printas la vetero por situo de la komandlinio. importado JSON, petoj, sys # Compute loko de komandlinio argumentoj. se len (sys.argv) <2: print ( 'Uzado: quickWeather.py loko') sys.exit () location = '' .join (sys.argv [1]) # TODO: Elŝutu la JSON datumoj de OpenWeatherMap.org API. # TODO: Laŭdu JSON datumoj en Python variablo.
En Pitono, komandlinio argumentoj estas stokitaj en la
sys.argv listo. Post la #! Shebang linio kaj import deklaroj, la programo kontrolos ke ekzistas pli ol unu komandlinio argumento. (Memoru ke sys.argv estos ĉiam almenaŭ unu elemento, sys.argv[0]
, kiu enhavas la Python script la dosiernomo.) Se estas nur unu
elemento en la listo, tiam la uzanto ne havigi lokon sur la komandlinio,
kaj "uzado" mesaĝo estos provizita al la uzanto antaŭ la programo
finiĝas.
Komandliniajn argumentojn disiĝas spacojn. La komandlinio argumento
San Francisco, CA farus sys.argv teni ['quickWeather.py', 'San', 'Francisco,', 'CA'] . Do nomas join() metodo por aliĝi ĉiuj kordoj krom la unua en sys.argv . Stoki ĉi aliĝis ĉenon en variablo nomata location . Paŝo 2: Elŝutu la JSON Datumoj
OpenWeatherMap.org provizas veran-tempa vetero informo en JSON formato. Via programo simple devas elŝuti la paĝon en http://api.openweathermap.org/data/2.5/forecast/daily?q=<Location>&cnt=3 , kie <Loko> estas la nomo de la urbo kies vetero volas . Aldonu la jenan al quickWeather.py.
#! python3 # QuickWeather.py - Printas la vetero por situo de la komandlinio. --snip-- # Elŝutu la JSON datumoj de OpenWeatherMap.org API. url = 'http: //api.openweathermap.org/data/2.5/forecast/daily? q =% s & CNT = 3'% (loko) respondo = requests.get (url) response.raise_for_status () # TODO: Laŭdu JSON datumoj en Python variablo.
Ni havas
location de nia komandlinio argumentoj. Fari la URL ni volas aliri, ni uzas la %s lokokupilon kaj enigaĵo ajn ŝnuro estas stokita en location en tiu punkto en la retadreso ŝnuro. Ni stoki la rezulton en url migru url al requests.get() . La requests.get() alvoko redonas Response objekto, kiun vi povas kontroli por eraroj nomante raise_for_status() . Se escepto estas levita, la elŝutita teksto estos en response.text . Paŝo 3: Laŭdu JSON Datumoj kaj Print Veter
La
response.text membro variablo tenas grandan ĉenon de JSON-formatita datumoj. Konverti tion al Python valoro, invitu json.loads() funkcio. La JSON datumoj aspektos ion kiel jene: { 'Urbo': { 'coord': { 'lat': 37,7771, 'lon': -122,42}, 'Lando': 'Unuiĝintaj Ŝtatoj de Ameriko', 'Id': '5391959', 'Nomo': 'Sankta Francisko', 'Loĝantaro' 0}, 'CNT': 3, 'Moruo': '200', 'Lerta': [{ 'nuboj' 0, 'Deg' 233, 'Dt': 1402344000, 'Humido': 58, 'Premo': 1012,23, 'Rapido': 1,96, 'Temp': { 'tago': 302,29, 'Hieraŭo': 296,46, 'Max': 302,29, 'Min': 289,77, 'Mateno': 294,59, 'Nokto': 289,77}, 'Vetero': [{ 'priskribo': 'ĉielo estas klara', 'Piktogramon': '01d', --snip--
Vi povas vidi ĉi datumojn pasante
weatherData al pprint.pprint() . Vi eble volas kontroli http://openweathermap.org/ por pli dokumentado sur kio tiuj kampoj signifi. Ekzemple, la linio dokumentado diros vin ke la 302.29 post 'day' estas la tagtempo temperaturo en Kelvin, ne Celsius aŭ Fahrenheit.
La vetero priskriboj volas turnigxis
'main' kaj 'description' . Al nete presi ilin, aldoni la sekvan al quickWeather.py. ! python3 # QuickWeather.py - Printas la vetero por situo de la komandlinio. --snip-- # Laŭdu JSON datumoj en Python variablo. weatherData = json.loads (response.text) # Presi vetero priskriboj. ❶ w = weatherData [ 'lerta'] print ( 'Nuna vetero en% s:'% (location)) print (w [0] [ 'vetero'] [0] [ 'ĉefa'], '-', w [0] [ 'vetero'] [0] [ 'priskribo']) print () presi ( 'Morgaŭ:') print (w [1] [ 'vetero'] [0] [ 'ĉefa'], '-', w [1] [ 'vetero'] [0] [ 'priskribo']) print () presi ( 'Tago postmorgaŭ:') print (w [2] [ 'vetero'] [0] [ 'ĉefa'], '-', w [2] [ 'vetero'] [0] [ 'priskribo'])
Rimarku kiel la kodo tendencas
weatherData['list'] en la variablo w savi vin iu tajpadon ❶. Vi uzas w[0] , w[1] kaj w[2] por elsxuti la vortarojn por hodiaŭ, morgaŭ, kaj postmorgaŭ la vetero, respektive. Ĉiu de ĉi tiuj vortaroj havas 'weather' klavon, kiu enhavas liston valoro.
Vi estas interesita en la unua listeron, oni nestitaj vortaro kun
pluraj pli klavoj, ĉe indeksa 0. Ĉi tie, ni presi la valoroj stokitaj en
la 'main' kaj 'description' klavoj, apartigitaj per streketo.
Kiam tiu programo kuras kun la komandlinio argumento
quickWeather.py San Francisco, CA , la eligo aspektas io tiamaniere: Nuna vetero en San Francisco, CA: Klara - ĉielo estas klara morgaŭ: Nuboj - kelkaj nuboj Tago post morgaŭ: Klara - ĉielo estas klara
(La vetero estas unu el la kialoj mi ŝatas vivi en Sankta Francisko!)
Ideoj por Similaj Programoj
Alirante meteorológica povas formi la bazon por multaj tipoj de programoj. Vi povas krei similajn programojn por fari la sekvajn:
- Kolekti vetero antaŭvidoj por pluraj kampadejoj aŭ hiking vojetoj vidi kiu havos la plej bonan veteron.
- Plani programon por regule kontroli la veteron kaj sendi vin frosto garde se vi devas movi vian plantoj endome. ( Ĉapitro 15 kovras temptabelanta kaj Ĉapitro 16 klarigas kiel sendi retpoŝton.)
- Tiri meteorológica de multoblaj ejoj montri subite, aŭ kalkuli kaj montri la mezumo de la multnombraj vetero prognozoj.
resumo
CSV kaj JSON estas komuna teksto formatoj por stoki datumojn.
Ili estas facile por programoj analizi dum ankoraŭ estante homa
legebla, tial ili estas ofte uzata por simpla kalkultabelojn aŭ ttt app
datumoj. La
csv kaj json moduloj ege simpligi la procezo de legado kaj skribado al CSV kaj JSON dosierojn.
La lastaj ĉapitroj instruis al vi kiel uzi Python analizi informojn el vasta gamo da formatoj. Unu komuna tasko prenas datumojn de vario de formatoj kaj sintaksa analizo por la aparta informoj vi bezonas. Tiuj taskoj estas ofte specifa por la punkto ke komerca programaro ne optimume helpema.
Skribante vian propran skriptoj, vi povas fari la komputilon manipuli
grandajn kvantojn de datumo prezentita en ĉi tiuj formatoj.
En ĉapitro 15 , vi rompos for de datumoj formatoj kaj lerni kiel fari vian programoj komuniki kun vi sendante retpoŝtojn kaj teksto mesaĝojn.
praktiko Demandoj
Q:
|
1. Kio estas kelkaj karakterizaĵoj Excel Spreadsheets esti ke CSV kalkultabelojn ne?
|
Q:
|
2. Kion vi pasas al
csv.reader() kaj csv.writer() por krei Reader kaj Writer objektoj? |
Q:
|
3. Kio modaloj ĉu
File celoj por leganto kaj Writer objektoj bezonas esti malfermita en? |
Q:
|
4. Kio metodo prenas liston argumento kaj skribas ĝin al CSV-dosieron?
|
Q:
|
5. Kion la
delimiter kaj lineterminator ŝlosilvorto argumentoj fari? |
Q:
|
6. Kio funkcio prenas ŝnuron el JSON datumoj kaj resendas Python datumstrukturo?
|
Q:
|
7. Kio funkcio prenas Python datumstrukturo kaj redonas ĉenon de JSON datumoj?
|
praktiko Projekto
Por praktiko, skribi programon kiu faras la sekvan.
Excel -al- CSV Konvertilo
Excel povas savi kalkultabelo por CSV-dosieron per kelkaj musklakoj,
sed se vi devis konverti centojn de Excel dosierojn al CSVs, necesus
horoj de alklako. Uzante la
openpyxl modulo de Ĉapitro 12 , skribi programon kiu legas ĉiujn Excel dosierojn en la nuna laboranta dosierujo kaj eligas ilin kiel CSV dosierojn.
Sola Excel dosiero povus enhavi multoblajn foliojn; vi devos krei CSV-dosiero por folio. La dosiernomoj de la CSV dosieroj devus esti <excel dosiernomo> _ <folio titolo> CSV, kie <excel dosiernomo> estas la dosiernomo de la Excel-dosiero sen la dosiersufikso (ekzemple,
'spam_data' , ne 'spam_data.xlsx' ) kaj <folio titolo> estas la ŝnuro de la Worksheet objekto title variablo.
Tiu programo implikos multaj nestitaj
for bukloj. La skeleto de la programo aspektas tiel: por excelFile en os.listdir ( '.'): # Skip ne- XLSX dosieroj, ŝarĝi la workbook objekto. por sheetName en wb.get_sheet_names (): # Loop tra ĉiu folio en la workbook. folio = wb.get_sheet_by_name (sheetName) # Krei la CSV dosiernomo de la Excel dosiernomo kaj folio titolo. # Krei la csv.writer objekto por ĉi CSVa dosiero. # Loop tra ĉiu vico en la folio. por rowNum en gamo (1, sheet.get_highest_row () + 1): rowData = [] # postglui ĉiu ĉelo al tiu listo # Loop tra ĉiu ĉelo en la vico. por colNum en gamo (1, sheet.get_highest_column () + 1): # Aligi ĉiu ĉelo datumoj por rowData. # Skribu rowData lerta al la CSV-dosiero. csvFile.close ()
Elŝuti la ZIP- dosiero excelSpreadsheets.zip de http://nostarch.com/automatestuff/ kaj maldensigi la kalkultabelojn en la sama dosierujo kiel via programo. Vi povas uzi tiujn kiel la dosierojn por testi la programon sur.
Nenhum comentário:
Postar um comentário