Ĉapitro 11 - TTT skrapante



Subtenu la Aŭtoro: Aĉeti la libron sur Amazono aŭ
la libro / ebook pakaĵo rekte Neniu amelo Gazetaro .

Legi la aŭtora aliaj liberaj Python libroj:



ttt skrapante
En tiuj maloftaj, terura momentoj kiam mi sen Wi-Fi, mi rimarkas kiom
multe de kion mi faras en la komputilo estas vere kion mi faras en
Interreto.
Pro simpla kutimo mi trovas min provas kontroli retpoŝton, legi amikoj
Twitter feeds, aŭ respondi la demandon: "Ĉu Kurtwood Smith havas ajnan
gravan roloj antaŭe li estis en la originala 1987 Robocop?" [ 2 ]
Ĉar tiel laboro sur komputilo engaĝas iranta sur la Interreto, ĝi estus granda se via programoj povis ricevi rete. Web skrapanta estas la termino por uzi programon por elŝuti kaj procezo enhavo de la TTT. Ekzemple, Google kuras multajn ttt skrapanta programoj indeksi retpaĝoj por lia serĉilon. En ĉi tiu ĉapitro vi lernos pri pluraj moduloj kiuj faciligi skrapi retpaĝoj en Python.
webbrowser. Venas kun Python kaj malfermas retumilo al specifa paĝo.- Petoj. Elŝutoj dosierojn kaj retpaĝoj de la Interreto.
- Bela Supo. Parses HTML, la formato kiu retpaĝoj estas skribita en.
- Seleno. Ĵetas kaj kontrolas retumilo. Seleno povas plenigi formoj kaj simuli musklakoj en tiu retumilo.
Projekto: mapit.py kun la webbrowser Modulo
La
webbrowser modulo open() funkcio povas lanĉi novan retumilon al specifa URL. Eniri la sekva en la interaga konko: >>> Import webbrowser >>> Webbrowser.open ( 'http://inventwithpython.com/')
Al retumilo langeto malfermos al la URL http://inventwithpython.com/ . Temas pri la sola afero la
webbrowser modulo povas fari. Malgraŭ tio, la open() funkcio faras fari interesajn aferojn ebla. Ekzemple, ĝi estas teda kopii strata adreso al la tondujo kaj elvoku mapon de ĝi sur Google Maps.
Vi povus preni kelkajn paŝojn for de tiu tasko por skribi simplan
skripton por aŭtomate lanĉi la mapo en via retumilo uzante la enhavon de
via tondujo. Tiel, vi nur devas kopii la adreson al tondujo kaj rulu la skripton, kaj la mapo estos ŝarĝitaj por vi.
Jen kion via programo faras:
- Ricevas Direkto de la komandlinio argumentoj aŭ tondujo.
- Malfermas la retumilo al la Google Maps paĝon por la adreso.
Tio signifas via kodo devos fari la sekvan:
- Legi la komandlinio argumentoj de
sys.argv. - Legi la tondujo enhavo.
- Voku la
webbrowser.open()funkcio malfermi la navegador retejo.
Malfermi novan dosieron redaktanto fenestro kaj savi ĝin kiel mapIt.py.
Paŝo 1: diveni la URL
Bazita sur la instrukciojn en Apendico B, starigita mapIt.py por ke kiam vi kuros ĝin de la komanda linio, kiel do ...
C: \> mapit 870 Valencia St, San Francisco, CA 94110
... La skripto uzas la komandliniajn argumentojn anstataŭ la tondujo. Se ne estas komandlinio argumentoj, tiam la programo scios uzi la enhavon de la tondujo.
Unue vi devas kalkuli ekstere kion URL uzi por donita strato adreso. Kiam vi ŝarĝi http://maps.google.com/ en la retumilo kaj serĉi adreson, la URL en la stango aspektas io tiamaniere: https://www.google.com/maps/place/870+Valencia
+ St / @ 37,7590311, -122.4215096,17z / data =! 3m1! 4b1! 4m2! 3m1!
1s0x808f7e3dadc07a37: 0xc86b0b2bb93b73d8 .
La adreso estas en la URL, sed ekzistas multe da aldonaj tekstoj ekzistas ankaŭ. Retejoj ofte aldonas ekstran datumojn al URLoj helpi aŭtoveturejo vizitantoj aŭ personecigi ejoj. Sed se vi provos simple tuj https://www.google.com/maps/place/870+Valencia+St+San+Francisco+CA/ , vi trovos ke ĝi ankoraŭ alportas supren la korekta paĝo. Do via programo povas esti agordita por malfermi per foliumilo por
'https://www.google.com/maps/place/ your_address_string' (kie your_address_string estas la adreso vi volas mapi). Paŝo 2: Manipuli la Komando Linio Argumentoj
Fari vian kodo aspektas kiel tio:
#! python3 # MapIt.py - Lanĉas mapon en la retumilo uzante adreson de la # Komandlinio aŭ tondujo. importado webbrowser, sys se len (sys.argv)> 1: # Akiri adreson el komandlinio. Adreso = '' .join (sys.argv [1]) # TODO: Get adreson el tondujo.
Post la programo
#! Shebang linio, vi devas importi la webbrowser modulo por ĵeti la retumilo kaj importi la sys modulo por legi la potencial komandlinio argumentoj. La sys.argv variablo tendencas listo de la programo dosiernomo kaj komandlinio argumentoj. Se tiu listo havas pli ol nur la dosiernomo sur gxi, tiam len(sys.argv) taksas al entjero pli granda ol 1 , signifante ke komandlinio argumentoj ja estis provizita.
Komandlinio argumentoj estas kutime apartigita per spacoj, sed en ĉi
tiu kazo, vi volas interpreti ĉiujn argumentojn kiel ununura linio. Ekde
sys.argv estas listo de kordoj, vi povas pasi ĝin al la join() metodon, kiu resendas ununuran ĉenon valoro. Vi ne volas la programo nomo en tiu ĉeno, do anstataŭ sys.argv , vi tradormos sys.argv[1:] haki for la unua elemento de la aro. La fina ŝnuro ke tiu esprimo taksas al estas stokita en la address variablo.
Se vi uzas programon enmetante ĉi en la komandlinio ...
mapit 870 Valencia St, San Francisco, CA 94110
... La
sys.argv variablo enhavos tiun liston valoro: [ 'MapIt.py', '870', 'Valencio' 'St,', 'Sankta', 'Francisko,', 'CA', '94110']
La
address variablo enhavos la ĉeno '870 Valencia St, San Francisco, CA 94110' . Paŝo 3: Manipuli la poŝo Enhavo kaj lanĉi legilon
Fari vian kodo aspektas kiel la sekvaj:
#! python3 # MapIt.py - Lanĉas mapon en la retumilo uzante adreson de la # Komandlinio aŭ tondujo. importado webbrowser, sys, pyperclip se len (sys.argv)> 1: # Akiri adreson el komandlinio. Adreso = '' .join (sys.argv [1]) alie: # Akiri adreson el tondujo. Adreso = pyperclip.paste () webbrowser.open ( 'https://www.google.com/maps/place/' + adreso)
Se ne estas komandlinio argumentoj, la programo supozos la adreso estas stokita en la tondujo. Vi povas akiri la tondujo enhavon kun
pyperclip.paste() kaj stoki ĝin en variablo nomata address . Fine, ĵeti foliumilo kun la Google Maps URL voki webbrowser.open() .
Dum iuj de la programoj vi skribas plenumos grandegaj taskoj kiuj savos
vin horojn, ĝi povas esti tiel kontentiga uzi programon kiu oportune
savas vin duaj ĉiufoje vi plenumi komunan taskon, kiel akiranta mapo
adreson. tabelo 11-1 komparas la paŝoj necesas por montri mapon kun kaj sen mapIt.py.
Tabelo 11-1. Prenanta Mapo kun kaj Sen mapIt.py
Permane akiranta mapo
|
uzante mapIt.py
|
|---|---|
Emfazi la adreso.
|
Emfazi la adreso.
|
Kopii la adreson.
|
Kopii la adreson.
|
Malfermu la foliumilon.
|
Kuri mapIt.py.
|
Iru http://maps.google.com/ .
| |
Klaki la adreson tekstujon.
| |
Almeti la adreson.
| |
Gazetara ENTER.
|
Vidu kiom mapIt.py faras tiun taskon malpli teda?
Ideoj por Similaj Programoj
Tiel longe kiel vi havas URL, la
webbrowser modulo permesas uzantoj eltranĉu la paŝo de malfermi la retumilo kaj direktante sin al retejo. Aliaj programoj povis uzi ĉi tiu funcionalidad por fari la sekvajn: - Malfermu cxiujn ligojn sur paĝo en apartaj retumilo langetoj.
- Malfermi la retumilo al la URL por via loka vetero.
- Malfermita pluraj socia reto ejoj kiujn vi regule kontrolu.
Elŝuti dosierojn el la interreto kun la petoj Modulo
La
requests
modulo permesas facile elŝuti dosierojn el la interreto sen devi
maltrankviligi kompliki aferojn kiel reto eraroj, rilato problemoj kaj
datuma kunpremo. La requests modulo ne venas kun Python, do vi devos instali ŝin unua. El la komandlinio, kuri pip install requests . (Apendico A havas kromajn informojn kiel instali triaj moduloj.)
La
requests modulo estis skribita ĉar Python urllib2 modulo estas tro komplika uzi. Fakte, preni permanentan markilo kaj nigra tiun tutan alineon. Forgesos min iam menciis urllib2 . Se vi bezonas elŝuti aferojn de la retejo, simple aliru la requests modulo.
Sekva, fari simplan teston por certigi la
requests modulo instalis sin ĝuste. Eniri la sekva en la interaga konko: >>> Import petoj
Se neniu erarmesaĝojn aperas, tiam la
requests modulo estis sukcese instalita. Elŝutanta retpaĝo kun la requests.get () Funkcio
La
requests.get() funkcio prenas kordoj de URL por elŝuti. Nomante type() sur requests.get() 's reveno valoro, vi povas vidi ke ĝi redonas Response objekton, kiu enhavas la respondon ke la retservilo donis por via peto. Mi klarigos la Response objekton pli detale poste, sed por nun, tajpu la sekvajn en la interaga ŝelo dum via komputilo estas konektita al la Interreto: >>> Import petoj >>> Res = requests.get ( 'https://automatetheboringstuff.com/files/rj.txt') >>> Tipo (res) <Klaso requests.models.Response '> ❶ >>> res.status_code == requests.codes.ok veraj >>> Len (res.text) 178981 >>> Print (res.text [250]) La Projekto Gutenberg EBook de Romeo kaj Julieta, de William Shakespeare Tiu eBook estas por la uzo de iu ajn ie ajn en neniu kosto kaj kun preskaŭ neniuj restriktoj whatsoever. Vi povas kopii ĝin, doni ĝin for aŭ re-uzi ĝin laŭ la kondiĉoj de la Proje
La URL iras al teksto retpaĝo por la tuta verko de Romeo kaj Julieta. Vi povas diri ke la peto por ĉi retpaĝo sukcedita fare kontrolanta la
status_code atributo de la Response objekto. Se ĝi estas egala al la valoro de requests.codes.ok , tiam ĉio iris bone ❶.
(Parenteze, la statuso kodo por "OK" en la HTTP- protokolon estas 200.
Vi povus jam esti familiara kun la 404 statuso kodo por "Not Found".)
Se la peto sukcesus, la elŝutita retpaĝo estas stokita kiel linio en la
Response objekto text variablo. Tiu variablo tenas grandan ĉenon de la tuta ludo; la alvoko al len(res.text) montras ke ĝi estas pli ol 178,000 signojn longa. Fine, nomante print(res.text[:250]) montras nur la unuaj 250 karakteroj. Kontrolanta por Eraroj
Kiel vi vidis, la
Response objekto havas status_code atributo kiu povas esti kontrolita kontraŭ requests.codes.ok vidi ĉu la malŝarĝo sukcesis. Pli simpla maniero por kontroli por sukceso estas nomi la raise_for_status() metodon sur la Response objekto. Tiu levos escepto se estis eraro elŝuti la dosieron kaj faros nenion, se la malŝarĝo sukcesis. Eniri la sekva en la interaga konko: >>> Res = requests.get ( 'http://inventwithpython.com/page_that_does_not_exist') >>> Res.raise_for_status () Traceback (plej lasta alvoko lasta): Dosiero "<pyshell # 138>", linio 1, en <modulo> res.raise_for_status () Dosiera "C: \ Python34 \ lib \ ejo-pakaĵoj \ petoj \ models.py", linio 773, en raise_for_status levi HTTPError (http_error_msg, respondo = mem) requests.exceptions.HTTPError: 404 Kliento Eraro: ne trovita
La
raise_for_status() metodo estas bona maniero de certigi ke programo haltas se malbona malŝarĝo okazas. Tio estas bona afero: vi volas, ke via programo por halti kiam iu neatendita eraro okazas. Se malsukcesa malŝarĝo ne estas interkonsento breaker por via programo, vi povas envolver la raise_for_status() linio kun try kaj except deklaroj manipuli ĉi eraro kazo sen kraŝanta. importado petoj res = requests.get ( 'http://inventwithpython.com/page_that_does_not_exist') provu: res.raise_for_status () krom Escepto kiel Excma: print ( 'Okazis problemo:% s'% (Excma))
Ĉi
raise_for_status() metodo alvoko kaŭzas la programo por eligi la sekvaj: Estis problemo: 404 Kliento Eraro: ne trovita
Ĉiam nomas
raise_for_status() post nomi requests.get() . Vi volas esti certa ke la malŝarĝo efektive laboris antaŭ via programo daŭras. Ŝparante elŝutita dosierojn al la Hard Drive
De tie, Vi povas savi la retpaĝon al dosiero sur via malfacila stirado kun la normo
open() funkcio kaj write() metodon. Estas iuj malgrandaj diferencoj, tamen. Unue, vi devas malfermi la dosieron en registran duuma reĝimo aprobante la ĉeno 'wb' kiel la dua argumento al open() . Eĉ se la paĝo estas en ebena teksto (kiel la Romeo kaj Julieta teksto vi elŝutis frue), vi devas skribi binarajn datumojn anstataŭ teksto datumoj por subteni la unikoda kodigo de la teksto.
Skribi la retpaĝon al dosiero, vi povas uzi
for buklo kun la Response objekto iter_content() metodo. >>> Import petoj >>> Res = requests.get ( 'https://automatetheboringstuff.com/files/rj.txt') >>> Res.raise_for_status () >>> PlayFile = malfermita ( 'RomeoAndJuliet.txt', 'WB) >>> Por bloko en res.iter_content (100000): playFile.write (bloko) 100000 78981 >>> PlayFile.close ()
La
iter_content() metodo revenas "pecoj" de la enhavo sur ĉiu ripeto tra la buklo. Ĉiu chunk estas de la bajtoj datumtipo, kaj vi ricevas specifi kiom da bajtoj ĉiu bloko enhavos. Cent mil bitokoj estas ĝenerale bona grandeco, tiel pasos 100000 kiel la argumento por iter_content() .
La dosiero RomeoAndJuliet.txt nun ekzistas en la aktuala labordosierujon. Notu ke dum la dosiernomo sur la retejo estis rj.txt, la dosiero sur via malfacila stirado havas malsaman dosiernomon. La
requests modulo simple pritraktas elŝuti la enhavon de retpaĝoj. Unufoje la paĝo estas malŝarĝita, ĝi estas simple datumojn en via programo. Eĉ se vi estis perdi vian Interretan konekton post malŝarĝi la retpaĝo, ĉiuj paĝon datumoj ankoraŭ estus en via komputilo.
La
write() metodon redonas la nombron de bitokoj skribis al la dosiero.
En la antaŭa ekzemplo, ekzistis 100,000 bajtoj en la unua bloko, kaj la
restanta parto de la dosiero bezonis nur 78.981 bitokoj.
Al revizio, jen la kompleta procezo por elŝuti kaj savi dosieron:
- Voku
requests.get()elŝuti la dosieron. - Nomas
open()kun'wb'krei novan dosieron en registran duuma reĝimo. - Buklo super la
Responseobjektoiter_content()metodo. - Voku
write()sur ĉiu ripeto skribi la enhavon de la dosiero. - Voku
close()por fermi la dosieron.
Jen ĉio estas al la
requests modulo! La for buklo kaj iter_content() aĵoj povas ŝajni komplikita kompare al la open() / write() / close() laborfluo vi estis uzante skribi tekston dosierojn, sed ĝi estas por certigi ke la requests modulo ne mangxas tro multa memoro eĉ se vi elŝutas amasa dosierojn. Vi povas lerni pri la requests modulo aliaj trajtoj de http://requests.readthedocs.org/ . HTML
Antaŭ vi elektas dise retpaĝoj, vi lernos iom da HTML basics. Vi ankaux vidos kiel aliri vian retumilon fortega desarrollador iloj, kiuj faros skrapante informoj el la TTT multe pli facila.
Rimedoj por lerni HTML
Hipertextual Markup Language (HTML)
estas la formato kiu retpaĝoj estas skribita. Tiu ĉapitro supozas vi
havas iujn bazajn sperto kun HTML, sed se vi bezonas komencanto lernilo,
mi sugestas unu el la jenaj lokoj:
A Rapida aktualigo
En kazo ĝi estas estita momento ekde vi rigardis ajnan HTML, jen rapidan superrigardon de la basics. HTML dosiero estas teksto dosiero kun la .html dosiersufikso. La teksto en tiuj dosieroj estas ĉirkaŭita per etikedoj, kiuj estas vortoj enmetitaj en angulo krampoj. La etikedoj diri la retumilo kiel formati la retpaĝo. Al komencante etikedo kaj fermo etikedo povas ĉirkaŭfermi tekston por formi ero. La teksto (aŭ ena HTML) estas la enhavo inter la komenca kaj ferma etikedoj. Ekzemple, jena HTML vidigas Saluton mondo! En la navegador, kun Saluton en aŭdaca:
<Strong> Saluton </ strong> mondo!
Ĉi HTML aspektos Figuro 11-1 en retumilo.
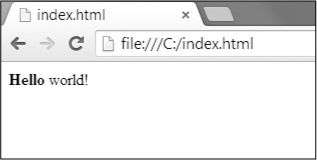
Figuro 11-1. Saluton mondo! Pruntitaj en la retumilo
La malfermo
<strong> etikedo diras ke la fermita teksto aperos en grasa skribo. La fermo </strong> etikedoj diras la retumilo kie la fino de la aŭdaca teksto.
Ekzistas multaj malsamaj etikedoj en HTML. Kelkaj el tiuj etikedoj havas ekstran propraĵoj en formo de atributojn ene la angulo krampoj. Ekzemple, la
<a> etikedo enfermas teksto kiu devus esti ligilo. La retadreso kiun la teksto ligilojn por determinas la href atributo. Jen ekzemplo: Al la libera <a href="http://inventwithpython.com"> Python libroj </a>.
Ĉi HTML aspektos Figuro 11-2 en retumilo.
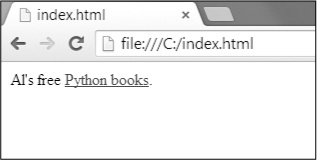
Figuro 11-2. La ligilon pruntitaj en la retumilo
Iuj elementoj havas
id atributo kiu estas uzata por unike identigi la elemento en la paĝo. Vi ofte instruu viajn programojn elserĉi elementon per ĝia id atributo, do elŝeligi elementon de id atributo uzante la retumilo programisto iloj estas komuna tasko skribe ttt skrapante programoj. Montrante la Fonto HTML de TTT Paĝo
Vi devas rigardi la HTML fonto de la TTT-paĝoj viaj programoj funkcios kun. Por fari tion, dekstra-klako (aŭ CTRL -click sur OS X) ajna retpaĝo en via foliumilo kaj elektu Vidi Fonto aŭ Vidi paĝo fonton por vidi la HTML teksto de la paĝo (vidu Figuron 11-3 ). Tiu estas la teksto via retumilo reale ricevas. La retumilo scias kiel montri, aŭ repagi, la retpaĝo de tiu HTML.
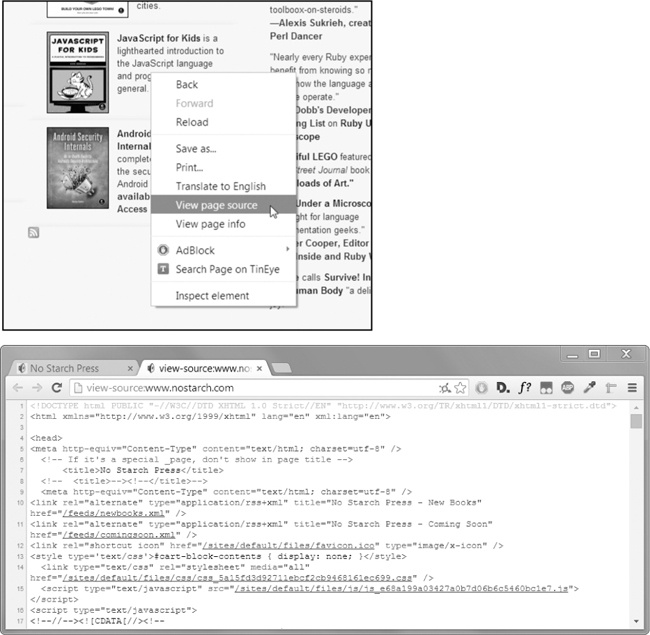
Figuro 11-3. Montrante la fonto de retpaĝo
Mi forte rekomendas vidi la fonto HTML de iuj viaj preferataj lokoj. Ĝi estas bone se vi ne plene komprenas kion vi vidas kiam vi rigardas la fonto. Vi ne bezonas HTML mastrado skribi simplan ttt skrapanta programoj-post ĉiu, vi ne skribas vian propran retejoj. Vi nur bezonos sufiĉan scion atentaro datumoj de ekzistanta retejo.
Malfermante via foliumilo Developer Iloj
Krom vidi retpaĝon fonto, oni povas vidi tiun HTML uzante via retumilo programisto iloj. En Chrome kaj Interreto Explorer por Windows, la programisto iloj jam instalita, Kaj vi povas premi F12 fari ilin aperi (vidu Figuron 11-4 ). Premante F12 denove faros la desarrollador iloj malaperas. En Chrome, Vi povas ankaŭ transporti la desarrollador iloj elektante View▸Developer▸Developer Iloj. En OS X, premante  - EBLO -mi malfermos Chrome la Developer Tools.
- EBLO -mi malfermos Chrome la Developer Tools.
- EBLO -mi malfermos Chrome la Developer Tools. 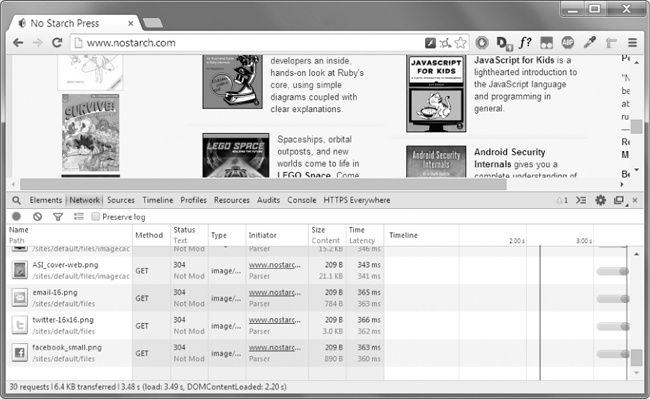
Figuro 11-4. La Developer Iloj fenestro en la Chrome retumilo
En Firefox, vi povas venigi la Retejo Developer Iloj Inspektisto premante CTRL - klavoj MAJUSKLIGA -C sur Vindozo kaj Linukso aŭ premante ⌘- EBLO -C sur OS X. La aranĝo estas preskaŭ identa al Chrome la desarrollador iloj.
En Safaro, malfermu la fenestron Preferoj, kaj sur la Altnivela panelo kontrolu la Show Disvolvi menuon en la menuo trinkejo opcion. Post ĝi ebligis, vi povas venigi la desarrollador iloj premante - EBLO -mi.
- EBLO -mi.
Post funkciigo aŭ instali la desarrollador iloj en via retumilo, vi povas dekstre-klaki ajnan parton de la retpaĝo kaj elektu Inspekti Elemento de la kunteksto menuo por porti la HTML respondeca ke parto de la paĝo. Tio estos utila kiam vi komencas analizi HTML por via TTT skrapante programoj.
Uzante la Developer Iloj Trovi HTML Elementoj
Unufoje via programo elŝutita retpaĝon uzante la
requests modulo, vi havos la paĝon HTML enhavo kiel ununura ĉeno valoro. Nun vi devas diveni kiu parto de la HTML respondas al la informoj sur la retpaĝo vi interesiĝas.
Ĉi tiu estas kie la retumilo programisto iloj povas helpi. Diru vi volas skribi programon por tiri veterprognozo datumoj de http://weather.gov/ . Antaŭ skribi ajnan kodon, fari iom esploron. Se vi vizitas la retejon kaj serĉi la 94105 poŝtkodo, la retejo prenos vin al paĝo montranta la prognozo por tiu areo.
Kio se vi estas interesita en skrapante la temperaturo informo por ke Poŝtkodo kodo? Dekstra-klaki kie estas sur la paĝo (aŭ KONTROLO -click sur OS X) kaj elektu Inspekti Elemento de la kunteksto menuo kiu aperas. Ĉi Venigu la Developer Iloj fenestro, kiu montras la HTML kiu produktas ĉi aparta parto de la retpaĝo. Figuro 11-5 montras la desarrollador iloj malfermitaj al la HTML de la temperaturo.
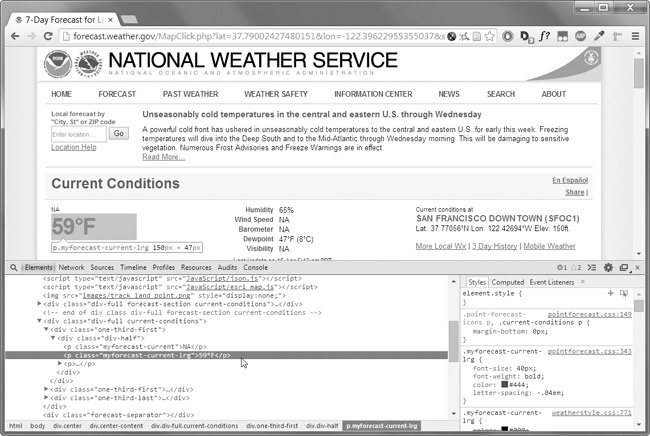
Figuro 11-5. Inspekti la elemento kiu tenas la temperaturon teksto kun la desarrollador iloj
De la ellaboranto iloj, vi povas vidi ke la HTML respondeca de la temperaturo parto de la retpaĝo estas
<p class="myforecast-current -lrg">59°F</p> . Tio estas precize kion vi serĉas! Ĝi similas ke la temperaturo informo estas enhavita ene de <p> elemento kun la myforecast-current-lrg klaso. Nun ke vi scias kion vi serĉas, la BeautifulSoup modulo helpos vin trovi gxin en la kordo. Sintaksa analizo HTML kun la BeautifulSoup Modulo
Bela Supo estas modulo por ĉerpi informon de HTML-paĝo (kaj estas multe pli bone por tiu celo ol regulesprimoj). La
BeautifulSoup modulo nomo estas bs4 (por Beautiful Soup, versio 4). Por instali ĝin, vi devas kuri pip install beautifulsoup4 de la komandlinio. (Kontrolu Apendico A por instrukcioj pri instalado triaj moduloj.) Dum beautifulsoup4 estas la nomo uzita por instalado, importi Belega Supo vi kuri import bs4 .
Por ĉi tiu ĉapitro, la Belega Supo ekzemploj analizi (te, analizi kaj identigi la regionojn) HTML dosiero en la malmola disko. Malfermi novan dosieron redaktanto fenestro en sencela, eniri la sekvan, kaj konservi ĝin kiel example.html. Alternative, elŝutu ĝin el http://nostarch.com/automatestuff/ .
<! - Jen la example.html ekzemple dosiero. -> <Html> <head> <title> La afiŝinto Titolo </ title> </ head> <Body> <P> Elŝutu mia <strong> Python </ strong> libro de <a href = "http: // inventwithpython.com "> mia retejo </a>. </ p> <P class = "slogano"> Lernu Python la facilan vojon! </ P> <P> Per <span id = "aŭtoro"> Al Sweigart </ span> </ p> </ Body> </ html>
Kiel vi povas vidi, eĉ simpla HTML-dosiero engaĝas multaj malsamaj
etikedoj kaj atributoj kaj aferoj rapide akiri konfuzanta kun kompleksaj
retejoj. Feliĉe, Belega Supo faras labori kun HTML multe pli facila.
Kreante BeautifulSoup Objekto de HTML
La
bs4.BeautifulSoup() funkcio necesas nomi per ĉeno enhavante la HTML ĝi analizi. La bs4.BeautifulSoup() funkcio redonas estas BeautifulSoup objekto. Eniri la sekva en la interaga ŝelo dum via komputilo estas konektita al la Interreto: >>> Import petoj, BS4 >>> Res = requests.get ( 'http://nostarch.com') >>> Res.raise_for_status () >>> NoStarchSoup = bs4.BeautifulSoup (res.text) >>> Tipo (noStarchSoup) <Klaso bs4.BeautifulSoup '>
Tiu kodo uzas
requests.get() elŝuti la ĉefa paĝo de la Neniu amelo Press retejo kaj tiam pasas la text atributo de la respondo al bs4.BeautifulSoup() . La BeautifulSoup objekto kiu revenas estas stokita en variablo nomata noStarchSoup .
Vi povas ankaŭ ŝarĝi HTML dosiero de via malmola disko pasante
File objekto al bs4.BeautifulSoup() . Eniri la sekva en la interaga ŝelo (certigi la example.html dosiero estas labordosierujon): >>> ExampleFile = malfermita ( 'example.html') >>> ExampleSoup = bs4.BeautifulSoup (exampleFile) >>> Tipo (exampleSoup) <Klaso bs4.BeautifulSoup '>
Unufoje vi havas
BeautifulSoup objekto, vi povas uzi liajn metodojn por lokalizi specifajn partojn de dokumento HTML. Trovanta Elemento kun la unuaranga () Metodo
Vi povas ricevi retpaĝo elemento de
BeautifulSoup objekto nomante la select() metodo kaj pasante kordo de CSS selector por la elemento vi serĉas. Selectores estas kiel regulaj esprimoj: Ili specifas mastro serĉi, en tiu kazo, en HTML paĝoj anstataŭ ĝenerala teksto kordoj.
Plena diskuto de CSS selector sintakso estas preter la kadro de tiu ĉi
libro (ekzistas bona seleccionador lernilo en la rimedoj je http://nostarch.com/automatestuff/ ), sed jen mallonga enkonduko al selectores. Tabelo 11-2 montras ekzemplojn de la plej komunaj CSS selector ŝablonoj.
Tabelo 11-2. Ekzemploj de CSS Selectores
Selector pasis al la
select() metodo |
Kongruas ...
|
|---|---|
soup.select('div') |
Ĉiuj elementoj nomis
<div> |
soup.select('#author') |
La elemento kun
id atributo de author |
soup.select('.notice') |
Ĉiuj elementoj kiuj uzas CSS
class atributon nomita notice |
soup.select('div span') |
Ĉiuj elementoj nomis
<span> internulojn ero nomita <div> |
soup.select('div > span') |
Ĉiuj elementoj nomis
<span> , kiuj estas rekte ene ero nomita <div> , kun neniu alia elemento inter |
soup.select('input[name]') |
Ĉiuj elementoj nomis
<input> kiuj havas name atributon kun ia valoro |
soup.select('input[type="button"]') |
Ĉiuj elementoj nomis
<input> kiuj havas atributo nomita type kun valoro button |
La diversaj seleccionador ŝablonoj povas esti kombinitaj por fari kompleksajn matĉoj. Ekzemple,
soup.select('p #author') kongruas ajna elemento kiu havas id atributo de author , kiel longa kiel ĝi estas ankaŭ ene de <p> elemento.
La
select() metodo revenos listo de Tag objektoj, kiuj estas kiel Beautiful Soup reprezentas HTML elemento. La listo enhavos unu Tag objekto por ĉiu matĉo en la BeautifulSoup objekto HTML. Etikedo valoroj povas esti pasita al la str() funkcio por montri la HTML etikedoj reprezentas. Etikedo valoroj ankaŭ havas attrs atributo kiu montras ĉiujn HTML atributoj de la etikedo kiel vortaro. Uzante la example.html dosiero de antaŭe, eniri la sekva en la interaga konko: >>> Import BS4 >>> ExampleFile = malfermita ( 'example.html') >>> ExampleSoup = bs4.BeautifulSoup (exampleFile.read ()) >>> Elems = exampleSoup.select ( '# aŭtoro) >>> Tipo (elems) <Klaso listo '> >>> Len (elems) 1 >>> Tipo (elems [0]) <Klaso bs4.element.Tag '> >>> Elems [0] .getText () 'Al Sweigart' >>> Str (elems [0]) '<Span id = "aŭtoro"> Al Sweigart </ span>' >>> Elems [0] .attrs { 'Id': 'aŭtoro'}
Tiu kodo devos tiri la elemento kun
id="author" el nia ekzemplo HTML. Ni uzu select('#author') redonas liston de ĉiuj elementoj kun id="author" . Ni stokas tiun liston de Tag objektoj en la variablo elems kaj len(elems) diras ni estas unu Tag objekto en la liston; tie estis unu matĉo. Nomante getText() sur la elemento redonas la elemento tekston, aŭ interna HTML. La teksto de elemento estas la enhavo inter la malfermo kaj fermo etikedoj: en tiu kazo, 'Al Sweigart' .
Pasante la elemento al
str() redonas kordoj kun la komenca kaj ferma etikedoj kaj la elemento tekston. Fine, attrs donas al ni vortaron kun la elemento de atributo, 'id' kaj la valoro de la id atributo, 'author' .
Vi povas ankaŭ tiri ĉiujn
<p> elementojn de la BeautifulSoup objekto. Eniri ĉi en la interaga konko: >>> PElems = exampleSoup.select (p) >>> Str (pElems [0]) '<P> Elŝutu mia <strong> Python </ strong> libro de <a href = "http: // inventwithpython.com "> mia retejo </a>. </ p> ' >>> PElems [0] .getText () 'Elŝutu mia Python libron de mia retejo.' >>> Str (pElems [1]) '<P class = "slogano"> Lernu Python la facilan vojon! </ P>' >>> PElems [1] .getText () 'Lernu Python la facilan vojon! >>> Str (pElems [2]) '<P> Per <span id = "aŭtoro"> Al Sweigart </ span> </ p>' >>> PElems [2] .getText () Per Al Sweigart '
Tiu tempo,
select() donas al ni liston de tri matĉoj, kiujn ni stokas en pElems . Uzante str() sur pElems[0] , pElems[1] , kaj pElems[2] montras ĉiun elementon kiel linio, kaj uzante getText() sur ĉiu elemento montras lian tekston. Getting Datumoj el Elemento la Atributoj
La
get() metodo por Tag objektoj igas simplan aliron atributo valoroj de ero. La metodo estas pasita kordo de atributo nomo kaj redonas tiu atributo valoro. Uzante example.html, eniri la sekva en la interaga konko: >>> Import BS4 >>> Supo = bs4.BeautifulSoup (malfermita ( 'example.html')) >>> SpanElem = soup.select ( 'interspaco') [0] >>> Str (spanElem) '<Span id = "aŭtoro"> Al Sweigart </ span>' >>> SpanElem.get ( 'id') 'Aŭtoro' >>> SpanElem.get ( 'some_nonexistent_addr') == None veraj >>> spanElem.attrs { 'Id': 'aŭtoro'}
Tie ni uzas
select() por trovi neniun <span> elementoj kaj tiam stoki la unua kongruis elemento en spanElem . Pasante la atributo nomo 'id' al get() redonas la atributo valoro, 'author' . Projekto: "Mi Bonŝancas" Google Search
Kiam mi serĉu temo en Google, mi ne rigardu nur serĉo rezulto samtempe. Per meza alklako serĉo rezulto ligilon (aŭ alklako tenante CTRL), mi malfermas la unuan pluraj ligiloj en faskon de novaj langetoj por legi poste.
Mi serĉu Google ofte sufiĉas ke tiu laborfluo-malfermanta mia retumilo,
serĉis temon kaj meza alklako plurajn ligojn unuope-estas teda.
Estus bone se mi povus simple tajpu serĉvortoj la komandlinio kaj havas
mia komputilo aŭtomate malfermi retumilo kun ĉiuj supro serĉrezultoj en
nova langetoj. Ni skribi skripton por fari tion.
Jen kion via programo faras:
- Ricevas serĉo ŝlosilvortoj de la komandlinio argumentoj.
- Rekuperas la serĉrezultoj paĝo.
- Malfermas retumilo langeto por ĉiu rezulto.
Tio signifas via kodo devos fari la sekvan:
- Legi la komandlinio argumentoj de
sys.argv. - Venigu la serĉo rezulto paĝoj kun la
requestsmodulo. - Trovi la ligilojn al ĉiu serĉo rezulto.
- Voku la
webbrowser.open()funkcio malfermi la navegador retejo.
Malfermi novan dosieron redaktanto fenestro kaj savi ĝin kiel lucky.py.
Paŝo 1: Akiri la Komando Linio Argumentoj kaj Peti la Serĉo Paĝo
Antaŭ kodigo ion, vi unue devas scii la URL de la serĉo rezulto paĝoj. Rigardante la retumilo adreso trinkejo post fari Google serĉo, vi povas vidi ke la rezulto paĝo havas URL kiel https://www.google.com/search?q=SEARCH_TERM_HERE . La
requests modulo povas elŝuti ĉi paĝo kaj tiam vi povas uzi Belega Supo trovi la serĉo rezulto ligilojn en la HTML. Fine, vi uzos la webbrowser modulo malfermi tiujn ligojn en retumilo langetoj.
Fari vian kodo aspektas kiel la sekvaj:
#! python3 # Lucky.py - Malfermas pluraj Google serĉrezultoj. importado petoj, sys, webbrowser, BS4 print ( 'Googling ...') # montriĝo teksto dum elŝutanta la Google paĝo res = requests.get ( 'http://google.com/search?q=' + '' .join (sys.argv [1])) res.raise_for_status () # TODO: Elsxuti supro serĉo rezulto ligilojn. # TODO: Malfermu retumilo langeto por ĉiu rezulto.
La uzanto specifas la serĉvorton uzante komandliniajn argumentojn kiam ĵetas la programon. Tiuj argumentoj estos stokitaj kiel kordoj en lerta en
sys.argv.Paŝo 2: Trovu Ĉiuj Rezultoj
Nun vi devas uzi Belega Supo ĉerpi la supro serĉo rezulto ligilojn de via elŝutita HTML. Sed kiel vi povas diveni, dekstre elektilo por la laborposteno? Ekzemple, vi ne povas simple serĉi por ĉiuj
<a>etikedoj, ĉar estas multaj ligiloj vi ne zorgas pri la HTML. Anstataŭe,
vi devas inspekti la serĉo rezulto paĝoj kun la retumilo programisto
iloj provi trovi seleccionador ke selektas nur la ligiloj vi volas.
Post fari Google serĉo por Beautiful Soup , vi povas malfermi la retumilo programisto iloj kaj inspekti iujn de la karmo elementoj sur la paĝo. Ili aspektas nekredeble komplika, io tiamaniere:
<a
href="/url?sa
=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&
amp;ved=0CCgQFjAA&url=http%3A%2F%2Fwww.crummy.com%2Fsoftware%2FBeautifulSoup
%2F&ei=LHBVU_XDD9KVyAShmYDwCw&usg=AFQjCNHAxwplurFOBqg5cehWQEVKi-TuLQ&a
mp;sig2=sdZu6WVlBlVSDrwhtworMA" onmousedown="return
rwt(this,'','','','1','AFQ
jCNHAxwplurFOBqg5cehWQEVKi-TuLQ','sdZu6WVlBlVSDrwhtworMA','0CCgQFjAA','','',ev
ent)"
data-href="http://www.crummy.com/software/BeautifulSoup/"><em>Beautiful
Soup</em>: We called him Tortoise because he taught us.</a>.
Ĝi ne importas ke la elemento aspektas nekredeble komplika. Vi nur bezonas trovi la mastron, ke ĉiuj serĉo rezulto ligilojn havas. Sed tiu
<a>elemento ne havas nenion kiu facile distingas ĝin de la nonsearch rezulto <a>elementoj sur la paĝo.
Fari vian kodo aspektas kiel la sekvaj:
#! python3 # Lucky.py - Malfermas pluraj google serĉrezultoj. importado petoj, sys, webbrowser, BS4 --snip-- # Elsxuti supro serĉo rezulto ligilojn. Supo = bs4.BeautifulSoup (res.text) # Malfermu retumilo langeto por ĉiu rezulto. LinkElems = soup.select ( '. R a')
Se vi rigardas supren iom de la
<a>ero, tamen, tie estas ero kiel ĉi: <h3 class="r">. Trarigardante la reston de la HTML fonto, ĝi aspektas kiel la rklaso estas uzata nur por serĉo rezulto ligilojn. Vi ne devas scii kion la CSS klaso restas aŭ kion ĝi faras. Vi simple tuj uzi ĝin kiel markilo por la <a>elemento vi serĉas. Kreu BeautifulSoupobjekto el la elŝutita paĝo HTML teksto kaj tiam uzi la seleccionador '.r a'trovi ĉiujn <a>elementojn kiuj estas ene elemento kiu havas la rCSS klaso.Paŝo 3: Open Web Browsers por Ĉiu Rezulto
Fine, ni informos la programon por malfermi retumilo langetoj por niaj rezultoj. Aldonu la sekvan al la fino de via programo:
#! python3 # Lucky.py - Malfermas pluraj google serĉrezultoj. importado petoj, sys, webbrowser, BS4 --snip-- # Malfermu retumilo langeto por ĉiu rezulto. linkElems = soup.select ( '. r a') numOpen = min (5, len (linkElems)) por i en gamo (numOpen): webbrowser.open ( 'http://google.com' + linkElems [i] .get ( 'href'))
Defaŭlte, vi malfermas la unuan kvin serĉo rezultigas novan langetoj uzante la
webbrowsermodulon. Tamen, la uzanto povas serĉis iun kiu aperis malpli ol kvin rezultojn. La soup.select()alvokon resendas liston de ĉiuj elementoj kiuj kongruis vian '.r a'selector, do la nombro de langetoj vi volas malfermi estas aŭ 5aŭ la longo de tiu listo (whikever estas pli malgranda).
La konstruita-en Python funkcio
min()redonas la plej malgrandan el la entjero aŭ flosi argumentoj estas pasita. (Ekzistas ankaŭ enkonstruita max()funkcio kiuredonas la plej grandan argumenton ĝi estas pasita.) Vi povas uzi min()por
malkovri ĉu ekzistas pli malmultaj ol kvin ligoj en la listo kaj stokas
la nombron de ligiloj por malfermi en variablo nomata numOpen. Tiam vi povas kuri tra formaŝo nomante range(numOpen).
Sur ĉiu ripeto de la ciklo, vi uzos
webbrowser.open()por malfermi novan langeton en la retumilo. Notu ke la hrefatributo valoro en la respondo <a>elementoj ne havas la komencan http://google.comparton, tiel vi devas concatenate ke la hrefatributo ĉenon valoro.
Nun vi povas tuj malfermos la unuan kvin Google rezultoj por, ni diru, Pitono programado lernilojn per kurado
lucky python programming tutorialssur la komandlinio! (Vidu Apendico B por kiom facile kuri programojn en via mastruma sistemo.)Ideoj por Similaj Programoj
Profito de pestañas navigacio estas ke vi povas facile malfermi ligilojn en nova langetoj al peruse poste. Programo kiu aŭtomate malfermiĝas plurajn ligojn samtempe povas esti bela ŝparvojo por fari la sekvajn:
- Malfermu cxiujn produkto paĝoj sercxis butikumada retejo kiel Amazono
- Malfermu ĉiujn ligilojn al recenzoj por unuopa produkto
- Malfermi la rezulto ligoj al fotoj post plenumante serĉu per foto ejo kiel Flickr aŭ Imgur
Projekto: Elŝutanta Ĉiuj XKCD Bildrakontoj
Blogoj
kaj aliaj regule ĝisdatiganta retejoj kutime havas frontpaĝo kun la
plej freŝa post tiel kiel Antaŭa butonon sur la paĝo kiu prenas vin al
la antaŭa post. Tiam tiu posteno ankaŭ havos Antaŭa
butonon, kaj tiel plu, kreante spuron de la plej lastatempaj paĝon por
la unua post en la retejo. Se vi volas kopion de la retejo enhavo legi kiam vi ne estas en linio, vi povus permane navigi sur ĉiu paĝo kaj savi ĉiun. Sed tiu estas sufiĉe enuiga laboro, do ni skribi programon por fari ĝin anstataŭe.
XKCD estas populara geek webcomic kun retejo kiu persvadas ĉi strukturo (vidu Figuron 11-6 ). La frontpaĝo ĉe http://xkcd.com/ havas Prev butono kiu gvidas la uzanton reen tra antaŭaj bildstrioj. Elŝuti ĉiun komika mane prenus ĉiam, sed oni povas skribi skripton por fari tion en kelkaj minutoj.
Jen kion via programo faras:
- Ŝarĝas la XKCD ĉefpaĝon.
- Ŝparas la komikaj bildo sur tiu paĝo.
- Sekvas la Antaŭa Comic ligilon.
- Ripetas ĝis ĝi atingas la unuan komikan.

Figuro 11-6. XKCD, "webcomic de romantikismo, sarkasmo, matematiko, kaj lingvo"
Tio signifas via kodo devos fari la sekvan:
- Download paĝoj kun la
requestsmodulo. - Trovi la URL de la komika bildo por paĝo uzante Belega supo.
- Elŝuti kaj savi la komikan bildon al la malmola disko kun
iter_content(). - Trovi la URL de la Antaŭa Comic ligilon, kaj ripeti.
Malfermi novan dosieron redaktanto fenestro kaj savi ĝin kiel downloadXkcd.py .
Paŝo 1: Desegni la Programo
Se vi malfermas la retumilo programisto iloj kaj inspekti la elementoj sur la paĝo, vi trovos la sekvan:
- La URL de la komika bildo dosiero estas donita per la
hrefatributo de<img>elemento. - La
<img>elemento estas ene<div id="comic">elemento. - La Prev butono havas
relHTML atributo kun la valoroprev. - La unua komikso Prev butono ligiloj al la http://xkcd.com/# URL indikante ke ne ekzistas pli antaŭaj paĝoj.
Fari vian kodo aspektas kiel la sekvaj:
#! python3
# DownloadXkcd.py - Elŝutoj ĉiu unuopa XKCD komika.
importado petoj, os, BS4
url = 'http://xkcd.com' # startanta url
os.makedirs ( 'xkcd', exist_ok = Vera) # vendejo bildstrioj en ./xkcd
dum ne url.endswith ( '#'):
# TODO: Elŝutu la paĝon.
# TODO: Trovi la URL de la komika bildo.
# TODO: Elŝutu la bildon.
# TODO: Savu la bildo al ./xkcd.
# TODO: Akiru la Prev butono url.
print ( 'Farita.')
Vi havos
urlvariablo kiu komenciĝas kun la valoro 'http://xkcd.com'kaj ree ĝisdatigi ĝin (en forbuklo) kun la URL de la aktuala paĝo estas Prev ligilon. Ĉiupaŝe en la buklo, vi elŝuti la komika ĉe url. Vi scios fini la buklo kiam urlfinas kun '#'.
Vi elŝuti la bildon dosierojn al dosierujo en la nuna labordosierujon nomita xkcd . La alvoko
os.makedirs()certigas ke tiu dosierujo ekzistas kaj la exist_ok=Trueŝlosilvorto argumento malhelpas la funkcion de ĵetante escepto se ĉi dosierujo jam ekzistas. La resto de la kodo estas ĝuste diras ke skizi la resto de via programo.Paŝo 2: Elŝutu la TTT Paĝo
Ni apliki la kodon por elŝuti la paĝon. Fari vian kodo aspektas kiel la sekvaj:
#! python3
# DownloadXkcd.py - Elŝutoj ĉiu unuopa XKCD komika.
importado petoj, os, BS4
url = 'http://xkcd.com' # startanta url
os.makedirs ( 'xkcd', exist_ok = Vera) # vendejo bildstrioj en ./xkcd
dum ne url.endswith ( '#'):
# Elŝutu la paĝon.
Print ( 'Elŝutado paĝo% s ...'% url)
res = requests.get (url)
res.raise_for_status ()
supo = bs4.BeautifulSoup (res.text)
# TODO: Trovi la URL de la komika bildo.
# TODO: Elŝutu la bildon.
# TODO: Savu la bildo al ./xkcd.
# TODO: Akiru la Prev butono url.
print ( 'Farita.')
Unua, presita
urlpor ke la uzanto scias kio URL la programo estas pri elŝuti; tiam uzi la requestsmodulo request.get()funkcio elŝuti ĝin. Kiel ĉiam, vi tuj voki la Responseobjekto raise_for_status()metodo ĵeti escepton kaj fini la programon se io fuŝiĝis kun la malŝarĝo. Alie, oni kreas BeautifulSoupobjekton de la teksto de la elŝutita paĝo.Paŝo 3: Trovu kaj uti la Comic Bildo
Fari vian kodo aspektas kiel la sekvaj:
#! python3 # DownloadXkcd.py - Elŝutoj ĉiu unuopa XKCD komika. importado petoj, os, BS4 --snip-- # Trovi la URL de la komika bildo. ComicElem = soup.select ( '# komika img') se comicElem == []: print ( 'Ne eblis trovi komikan bildon.') alie: provu: comicUrl = 'http:' + comicElem [0] .get ( 'fonto') # Elŝuti la bildo. print ( 'Elŝutanta bildo% s ...'% (comicUrl)) res = requests.get (comicUrl) res .raise_for_status () krom requests.exceptions.MissingSchema: # salti ĉi komika prevLink = soup.select ( 'a [rel = "prev"]') [0] url = 'http://xkcd.com' + prevLink.get ( 'href') daŭrigi # TODO: Savu la bildo al ./xkcd. # TODO: Akiru la Prev butono url. print ( 'Farita.')
De inspekti la XKCD hejmpaĝo kun via ellaboranto iloj, vi scias, ke la
<img>ero por la komikaj bildo estas ene <div>elemento kun la idatributon por comic, tial la seleccionador '#comic img'akiros vin la ĝusta <img>ero de la BeautifulSoupobjekto.
Kelkaj XKCD paĝoj havas specialan enhavon kiu ne estas simpla bildo dosiero. Tio estas bone; vi nur preterpasas tiujn. Se via selector ne trovas ajnan elementoj, tiam
soup.select('#comic img')revenos malplenan liston. Kiam tio okazas, la programo povas simple presi erarmesagxon kaj pluiru sen malŝarĝi la bildon.
Alie, la seleccionador revenos listo enhavanta unu
<img>ero. Vi povas akiri la srcatributo de tiu <img>elemento kaj fordoni al requests.get()elŝuti la komikaj bildo dosiero.Paŝo 4: Savu la Bildo kaj Trovu la Antaŭa Comic
Fari vian kodo aspektas kiel la sekvaj:
#! python3 # DownloadXkcd.py - Elŝutoj ĉiu unuopa XKCD komika. importado petoj, os, BS4 --snip-- # Konservu la bildon por ./xkcd. ImageFile = malfermita (os.path.join ( 'xkcd', os.path.basename (comicUrl)), 'WB') por bloko en res.iter_content (100000): imageFile.write (bloko) imageFile.close () # Akiri la Prev butono url. PrevLink = soup.select ( 'a [rel = "prev"]') [0] url = 'http://xkcd.com' + prevLink.get ( 'href') print ( 'Farita.')
Ĉe tiu punkto, la bildo dosiero de la komika estas stokita en la
resvariablo. Vi devas skribi ĉi bildo datumoj al dosiero sur la malmola disko.
Vi bezonos dosiernomo por la loka bildo dosiero pasi al
open(). La comicUrlhavos valoron kiel 'http://imgs.xkcd.com/comics/heartbleed_explanation.png'-kiu vi eble rimarkis aspektas multe kiel arkivo vojon. Kaj fakte, vi povas voki os.path.basename()kun comicUrl, kaj ĝi revenos nur la fina parto de la URL 'heartbleed_explanation.png'. Vi povas uzi tiun kiel la dosiernomo savinte la bildon al via malmola disko. Vi aliĝi tiun nomon kun la nomo de via xkcddosierujo uzante os.path.join()por ke via programo uzas deklivaj streketoj ( \) sur Windows kaj antaŭen slashes ( /) sur OS X kaj Linukso. Nun ke vi fine havos la dosiernomo, vi povas voki open()malfermi novan dosieron en 'wb'"skribas duuma" reĝimo.
Memoras de antaŭaj en tiu ĉapitro kiu savi dosierojn vi elŝutis uzante Petoj, vi devas buklo super la reveno valoro de la
iter_content()metodo. La kodo en la forbuklo skribas el pecoj de la bildo datumoj (maksimume 100,000 bajtoj ĉiu) al la dosiero kaj poste vi fermas la dosiero. La bildo estas nun konservita al via malmola disko.
Poste, la selector
'a[rel="prev"]'identigas la <a>elemento kun la relatributon al prevkaj vi povas uzi ĉi <a>elemento hrefatributon por ricevi la antaŭa komika la URL kiun prenas stokitaj en url. Tiam la whileciklo komencas la tuta malŝarĝo procezo denove por tiu komika.
La eligo de ĉi tiu programo aspektos tiel ĉi:
Elŝutanta paĝon http: //xkcd.com ...
Elŝuti bildo http: //imgs.xkcd.com/comics/phone_alarm.png ...
Elŝutanta paĝon http: //xkcd.com/1358 / ...
Elŝuti bildo http: //imgs.xkcd.com/comics/nro.png ...
Elŝutanta paĝon http: //xkcd.com/1357 / ...
Elŝuti bildo http: //imgs.xkcd.com/comics/free_speech.png ...
Elŝutanta paĝon http: //xkcd.com/1356 / ...
Elŝuti bildo http: //imgs.xkcd.com/comics/orbital_mechanics.png ...
Elŝutanta paĝon http: //xkcd.com/1355 / ...
Elŝuti bildo http: //imgs.xkcd.com/comics/airplane_message.png ...
Elŝutanta paĝon http: //xkcd.com/1354 / ...
Elŝuti bildo http: //imgs.xkcd.com/comics/heartbleed_explanation.png ...
--snip--
Tiu
projekto estas bona ekzemplo de programo kiu povas aŭtomate sekvi
ligojn por skrapadi grandajn kvantojn de datumoj el la TTT. Vi povas lerni pri Beautiful Soup la aliaj karakterizaĵoj de lia dokumentado ĉe http://www.crummy.com/software/BeautifulSoup/bs4/doc/ .
Ideoj por Similaj Programoj
Elŝutanta paĝoj kaj sekvante ligoj estas la bazo de multaj TTT rampanta programoj. Similaj programoj ankaŭ povis fari la sekvajn:
- Asist tuta paĝaro de sekvanta ĉiujn de liaj ligoj.
- Kopii ĉiujn mesaĝojn ekstere ttt forumo.
- Duobligi la katalogo de eroj por vendo sur reta vendejo.
La
requestskaj BeautifulSoupmoduloj estas grandaj kiel longe kiel vi povas diveni la URL vi bezonas pasi al requests.get(). Tamen, kelkfoje tio ne estas tiel facila de trovi. Aŭ eble la retejo vi volas vian programon por navigi postulas vin ensaluti unue. La seleniummodulo donos viajn programojn la potencon elfari tiajn kompleksajn taskojn.Kontrolante la legilo kun la seleno Modulo
La
seleniummodulo
permesas Python rekte kontroli la retumilo programmatically klakante
ligojn kaj plenigi salutinformon, preskaŭ kvazaŭ ekzistas homa uzanto
interagas kun la paĝo. Seleno permesas interagi kun retpaĝoj en multe pli progresinta maniero ol Petoj kaj Bela supo; sed
ĉar ĝi ĵetas foliumilo, ĝi estas iom malrapida kaj malfacila por kuri
en la fono se, ekzemple, vi nur bezonas elŝuti iuj dosierojn de la TTT.
Apendico A havas pli detalajn paŝojn sur instali triaj moduloj.
Komencanta Seleno-Controlled Foliumilo
Por tiuj ekzemploj, vi bezonos la Firefox retumilo. Tio estos la navegador kiu kontrolas. Se vi ne jam havas Firefox, vi povas elŝuti ĝin senpage el http://getfirefox.com/ .
Importante la moduloj por Seleno estas iomete malfacila. Anstataŭ
import selenium, vi devas kuri from selenium import webdriver. (La ĝusta tial la seleniummodulo enkadriĝas tien estas preter la kadro de tiu ĉi libro.) Post tio, vi povas lanĉi la Firefox retumilo kun seleno. Eniri la sekva en la interaga konko: >>> De seleno importado webdriver >>> retumilo = webdriver.Firefox () >>> tipo (retumilo) <Klaso selenium.webdriver.firefox.webdriver.WebDriver '> >>> Browser.get ( 'http://inventwithpython.com')
Vi rimarkos kiam
webdriver.Firefox()estas nomita, la Firefox retumilo funkciigas. Vokante type()sur la valoro webdriver.Firefox()malkaŝas estas la WebDriverdatumtipo. Kaj kunvokon browser.get('http://inventwithpython.com')direktas la retumilo al http://inventwithpython.com/ . Via retumilo devus rigardi ion kiel Figuro 11-7 .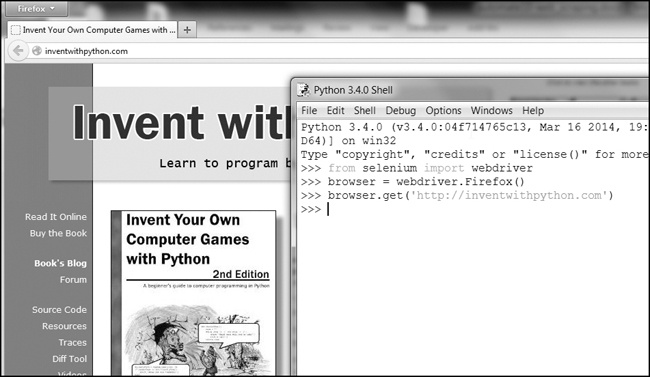
Figuro 11-7. Post nomi
webdriver.Firefox()kaj get()en sencela, la Firefox retumilo aperas.Trovante Elementoj sur la paĝo
WebDriverobjektoj havas tre kelkajn metodojn por trovi elementojn en paĝo. Ili estas dividitaj en la find_element_*kaj find_elements_*metodoj. La find_element_*metodoj reveni sola WebElementobjekto, reprezentante la unuan elementon sur la paĝo kiu kongruas vian pridemandon. La find_elements_*metodoj resendas liston de WebElement_*celoj por ĉiu egalante elemento sur la paĝo.
Tabelo 11-3 montras plurajn ekzemplojn de
find_element_*kaj find_elements_*metodoj vokite sur WebDriverobjekto kiu estas stokita en la variablo browser.
Tabelo 11-3. Seleno la
WebDriverMetodoj por Finding Elementoj
telefono nomon
|
WebElement objekto / lerta revenis
|
|---|---|
browser.find_element_by_class_name ( nomo ) browser.find_elements_by_class_name ( nomo ) |
Elementoj kiuj uzas la CSS klaso
name |
browser.find_element_by_css_selector ( elektilo ) browser.find_elements_by_css_selector ( elektilo ) |
Elementoj kiuj kongruas la CSS
selector |
browser.find_element_by_id ( id ) browser.find_elements_by_id ( id ) |
Elementoj kun trafa
idatributo valoro |
browser.find_element_by_link_text ( teksto ) browser.find_elements_by_link_text ( teksto ) | <a>elementoj kiuj tute kongruas al la textprovizita |
browser.find_element_by_partial_link_text ( teksto ) browser.find_elements_by_partial_link_text ( teksto ) | <a>elementoj kiuj enhavas la textprovizita |
browser.find_element_by_name ( nomo ) browser.find_elements_by_name ( nomo ) |
Elementoj kun trafa
nameatributo valoro |
browser.find_element_by_tag_name ( nomo ) browser.find_elements_by_tag_name ( nomo ) |
Elementoj kun trafa etikedo
name(kazo sensenta; an <a>elemento estas egalita per 'a'kaj 'A') |
Krom la
*_by_tag_name()metodoj, la argumentoj por ĉiuj metodoj estas usklecodistinga. Se neniu elementoj ekzistas en la paĝo kiu kongruas kion la metodo serĉas, la seleniummodulo levas NoSuchElementescepton. Se vi ne deziras tiun escepton frakasi vian programon, aldoni trykaj exceptdeklaroj al via kodo.
Unufoje vi havas la
WebElementcelon, vi povas eltrovi pli pri tio legante la atributoj aŭ nomante la metodoj en Tabelo 11-4 .
Tabelo 11-4. WebElement Atributoj kaj Metodoj
Atributo aŭ metodo
|
priskribo
|
|---|---|
tag_name |
La etikedo, ekz
'a'por <a>elemento |
get_attribute( name ) |
La valoron por la elemento
nameatributon |
text |
La teksto ene de la elemento, kiel
'hello'en<span>hello</span> |
clear() |
Por teksto kampo aŭ tekstkampon elementoj, tuŝetas la teksto tajpita en ĝin
|
is_displayed() |
Revenas
Truese la elemento estas videbla; alie revenojFalse |
is_enabled() |
Por enigo elementoj, denove
Truese la elemento estas ebligita; alie revenojFalse |
is_selected() |
Por markobutono aŭ radioaparato butono elementoj, denove
Truese la elemento estas elektita; alie revenojFalse |
location |
Al vortaro kun klavoj
'x'kaj 'y'por la pozicio de la elemento en la paĝo |
Ekzemple, malfermi novan dosieron redaktanto kaj eniri la sekvan programon:
de seleno importado webdriver
retumilo = webdriver.Firefox ()
browser.get ( 'http://inventwithpython.com')
provu:
Elem = browser.find_element_by_class_name ( 'bookcover')
presi ( 'Trovis <% s> elemento kun tiu klaso nomon!'% (elem.tag_name))
krom:
print ( 'Ĉu ne povis trovi elementon kun tiu nomo.')
Tie ni malfermas Firefox kaj direkti ĝin al retadreso. Sur tiu paĝo, ni provos trovi elementojn kun la klasnomo
'bookcover', kaj se tia ero estas trovita, ni presi lian etikedo nomon uzante la tag_nameatributo. Se ne tia ero estis trovita, ni presi malsaman mesaĝon.
Tiu programo volo eligo la sekvaj:
Trovita <img> elemento kun tiu klaso nomon!
Ni trovis ero kun la klasnomo
'bookcover'kaj la etikedo nomo 'img'.Klakante la Paĝo
WebElementobjektoj revenis de find_element_*kaj find_elements_*metodoj havas click()metodon kiu simulas musklako sur tiu ero. Tiu
metodo povas esti uzata por sekvi ligilon, fari elekton sur
radio-butonon, alklaku Submetu butonon, aŭ ellasilon ajn alie povas
okazi kiam la elemento estas klakis per la muso. Ekzemple, tajpu la sekvajn en la interaga konko: >>> De seleno importado webdriver >>> retumilo = webdriver.Firefox () >>> browser.get ( 'http://inventwithpython.com') >>> linkElem = browser.find_element_by_link_text ( 'Read It Online) > >> tipo (linkElem) <Klaso selenium.webdriver.remote.webelement.WebElement '> >>> LinkElem.click () # sekvas la "Read It Online" ligilo
Tiu malfermas Firefox por http://inventwithpython.com/~~V , Akiras la
WebElementcelon por la <a>elemento kun la teksto Read It Online , kaj tiam simulas klakante ke <a>elemento. Ĝi estas kvazaŭ vi alklakis mem; la retumilo tiam sekvas ligantaj.Plenigado kaj sendado Formoj
Sendanta keystrokes al teksto kampo en retpaĝo estas afero de trovanta la
<input>aŭ <textarea>elemento por ke teksto kampo kaj tiam nomante la send_keys()metodo. Ekzemple, tajpu la sekvajn en la interaga konko: >>> De seleno importado webdriver >>> retumilo = webdriver.Firefox () >>> browser.get ( 'https://mail.yahoo.com') >>> emailElem = browser.find_element_by_id ( 'login-username' ) >>> emailElem.send_keys ( 'not_my_real_email') >>> passwordElem = browser.find_element_by_id ( 'login-passwd') >>> passwordElem.send_keys ( '12345') >>> passwordElem.submit ()
Tiel longe kiel Gmail ne ŝanĝis la
idde
la salutnomon kaj pasvorton teksto kampoj ekde tiu libro estis
eldonita, la antaŭa kodo plenigos en tiuj tekstoj kampoj kun la
provizita tekston. (Vi povas ĉiam uzi la retumilo inspektisto por kontroli la id.) Nomante la submit()metodo
sur ajna elemento havos la saman rezulton kiel klakante la Submetu
butonon por la formo kiu elemento estas en. (Vi povus havi same facile
vokis emailElem.submit(), kaj la kodo estus faris la samon.)Sendante Specialaj Ŝlosiloj
Seleno havas modulon por klavaro klavoj kiuj estas neeble tajpi en kordo valoro, kiu funkciis tre kiel eskapo karakteroj. Tiuj valoroj estas stokitaj en atributoj en la
selenium.webdriver.common.keysmodulo. Ĉar tio estas tia longa modulo nomo, ĝi estas multe pli facile kuri from selenium.webdriver.common.keys import Keysĉe la supro de via programo; se vi faros, tiam vi povas simple skribi Keysie vi volas kutime devi skribi selenium.webdriver.common.keys. Tabelo 11-5 listigas la komune uzataj Keysvariabloj.
Tabelo 11-5. Komune Uzita Variabloj en la
selenium.webdriver.common.keysmodulo
atributoj
|
signifoj
|
|---|---|
Keys.DOWN, Keys.UP, Keys.LEFT,Keys.RIGHT |
La klavaro sagoklavoj
|
Keys.ENTER , Keys.RETURN |
La ENENklavon kaj reveno klavoj
|
Keys.HOME, Keys.END, Keys.PAGE_DOWN,Keys.PAGE_UP |
La
home, end, pagedown, kaj pageupklavoj |
Keys.ESCAPE, Keys.BACK_SPACE,Keys.DELETE |
La ESC , Backspace kaj DELETE klavoj
|
Keys.F1, Keys.F2, ...,Keys.F12 |
La F1 al F12 klavojn ĉe la supro de la klavaro
|
Keys.TAB |
La TAB ŝlosilo
|
Ekzemple, se la kursoro ne estas nuntempe en teksta kampo, premante la HEJMO kaj END klavoj rulumi la retumilo al la supro kaj malsupro de la paĝo, respektive. Eniri la sekva en la interaga ŝelo, kaj rimarki kiel la
send_keys()alvokoj rulumi la paĝon:>>> De seleno importado webdriver >>> de selenium.webdriver.common.keys importi Ŝlosiloj >>> retumilo = webdriver.Firefox () >>> browser.get ( 'http://nostarch.com') >>> htmlElem = browser.find_element_by_tag_name ( 'html') >>> htmlElem.send_keys (Keys.END) # rulumas al malsupro >>> htmlElem.send_keys (Keys.HOME) # rulaĵoj supren
La
<html> etikedo estas la bazo etikedo en HTML dosierojn: la kompleta enhavo de la HTML-dosiero estas enfermita ene la <html>kaj </html>etikedoj. Voko browser.find_element_by_tag_name('html')estas bona loko por sendi ŝlosilojn al la ĝenerala retpaĝo. Tio estus utila se, ekzemple, nova enhavo estas ŝarĝita iam vi scrolled al la fundo de la paĝo.Alklako Browser Butonoj
Seleno povas simuli klakoj en diversaj retumilo butonoj tiel tra la sekvaj metodoj:
browser.back(). Klakas la butonon Reen.browser.forward(). Klakas la Antaŭen butonon.browser.refresh(). Klakas la Refresh / Reŝarĝi butonon.browser.quit(). Klakas la Fermi fenestron butonon.
Pli Informo sur Seleno
Seleno povas fari multe pli preter la funkcioj priskribitaj tie. Ĝi povas modifi via retumilo kuketoj, prenu ekrankopioj de retpaĝoj kaj kuri kutimo Javascript. Lerni pli pri ĉi tiuj karakterizaĵoj, vi povas viziti la Seleno dokumentado ĉe http://selenium-python.readthedocs.org/ .
resumo
Plej enuigaj taskoj ne estas limigitaj al la dosieroj sur via komputilo. Povi programmatically elŝuti retpaĝoj pligrandigos vian programoj por Interreto. La
requestsmodulo faras elŝutanta simpla kaj kun iuj bazaj konoj de HTML konceptoj kaj selectores, vi povas uzi la BeautifulSoupmodulon por analizi la paĝoj vi elŝuti.
Sed por plene aŭtomatigi ajna TTT-bazita taskojn, vi bezonas rektan kontrolon de via retumilo tra la
seleniummodulo. La seleniummodulo permesas al vi ensaluti al retejoj kaj plenigi formoj aŭtomate. Ekde
foliumilo estas la plej ofta maniero por sendi kaj ricevi informon en
la Interreto, ĉi tiu estas granda kapablo havas en via programisto
ilaro.praktiko Demandoj
Q:
|
1. Mallonge priskribi la diferencojn inter la
webbrowser, requests, BeautifulSoup, kaj seleniummoduloj. |
Q:
|
2. Kio tipo de objekto revenis por
requests.get()? Kiel vi povas aliri la elŝutita enhavon kiel linio valoron? |
Q:
|
3. Kion Petas metodo ĉekojn ke la malŝarĝo laboris?
|
Q:
|
4. Kiel povas vin akiras la HTTP- statuso kodo de Petoj respondo?
|
Q:
|
5. Kiel vi savi Petoj respondo al dosiero?
|
Q:
|
6. Kio estas la klavaro ŝparvojo por malfermi la navegador estas developer iloj?
|
Q:
|
7. Kiel vi povas vidi (en la desarrollador iloj) la HTML de specifa elemento en retpaĝo?
|
Q:
|
8. Kio estas la CSS selector ĉeno kiu trovus la elemento kun
idatributo de main? |
Q:
|
9. Kio estas la CSS selector ĉeno kiu trovus la elementoj kun CSS klaso de
highlight? |
Q:
|
10. Kio estas la CSS selector ĉeno kiu trovus cxiujn
<div>elementojn ene alia <div>elemento? |
Q:
|
11. Kio estas la CSS selector ĉeno kiu trovus la
<button>elemento kun valueatributon por favorite? |
Q:
|
12. Diru vi havas Belega Supo
Tagobjekto stokitaj en la variablo spampor la elemento <div>Hello world!</div>. Kiel povis vin akiras kordo 'Hello world!'de la Tagobjekto? |
Q:
|
13. Kiel vi stoki ĉiujn atributojn de Beautiful Soup
Tagobjekto en variablo nomata linkElem? |
Q:
|
14. Running
import seleniumne funkcias. Kiel vi konvene importi la seleniummodulo? |
Q:
|
15. Kio estas la diferenco inter la
find_element_*kaj find_elements_*metodoj? |
Q:
|
16. Kio metodoj Seleno la
WebElementceloj havas por simuli musklakoj kaj klavaro klavoj? |
Q:
|
17. Vi povus voki
send_keys(Keys.ENTER)sur la Submetu butonon La WebElementobjekto, sed kio estas pli facila vojo por prezenti formo kun Seleno? |
Q:
|
18. Kiel vi povas simuli klakante retumilo Antaŭen, Malantaŭen, kaj Refresh butonoj kun Seleno?
|
praktiko Projektoj
Por praktiko, skribi programojn por fari la sekvajn taskojn.
Komando Linio Emailer
Skribi
programon kiu prenas retadreson kaj ŝnuro de teksto sur la komandlinio
kaj tiam, uzante Seleno, registras en vian retpoŝtan konton kaj sendas
retpoŝton de la ŝnuro al la provizita adreso. (Vi eble volas starigi apartan retpoŝtan konton por tiu programo.)
Tio estus bela maniero por aldoni sciigo karakterizaĵo viaj programoj. Vi povus ankaŭ skribi similan programon por sendi mesaĝojn de Facebook aŭ Twitter konton.
Image retejo Downloader
Skribi
programon kiu iras al foto-interŝanĝo ejo kiel Flickr aŭ Imgur, serĉoj
por kategorio de fotoj, kaj poste elŝutas ĉiuj bildoj resultantes. Vi povus skribi programon kiu funkcias kun ajna foto ejo kiu havas serĉo funkcio.
2048
2048 estas simpla ludo kie vi kombini kaheloj de glitante ilin supre, sube, maldekstra, aŭ dekstra kun la sagoklavoj. Vi povas reale preni sufiĉe altan poentaron de multfoje glitante en supren, dekstren, malsupren kaj lasis mastron saciedad. Skribi programon kiu malfermos la ludo ĉe https://gabrielecirulli.github.io/2048/ gardu sendas supren, dekstren, malsupren kaj maldekstren pulsbatoj por aŭtomate ludos la ludon.
ligilo Verification
Skribi programon kiu, donita la URL de retpaĝo, provos elŝuti ĉiun ligitaj paĝon sur la paĝo. La programo devus flago ajna paĝoj havas 404 "Not Found" statuso kodo kaj presi gxin kiel rompita ligojn.
Nenhum comentário:
Postar um comentário