Ĉapitro 13 - Laborante kun PDF kaj Word Dokumentoj



Subtenu la Aŭtoro: Aĉeti la libron sur Amazono aŭ
la libro / ebook pakaĵo rekte Neniu amelo Gazetaro .

Legi la aŭtora aliaj liberaj Python libroj:



Laborante kun PDF kaj vorto Dokumentoj
PDF kaj Word dokumentoj estas binaraj dosieroj, kiu igas ilin multe pli kompleksa ol teksto dosierojn. Krom teksto, ili stokas multan tiparo, koloro kaj aranĝo informon.
Se vi volas vian programojn por legi aŭ skribi al PDFs aŭ Word
dokumentoj, vi devas fari pli ol simple pasigas sian dosiernomojn por
open() .
Feliĉe, estas Python moduloj kiuj faras ĝin facila por vi por interagi kun PDFs kaj Word dokumentoj. Ĉi tiu ĉapitro kovras du tiajn modulojn: PyPDF2 kaj Python-docx.
PDF Dokumentoj
PDF signifas Portable Document Format kaj uzas la .pdf dosiersufikso.
Kvankam PDFs apogas multajn funkciojn, ĉi ĉapitro temos pri la du
aferoj vi estos faranta plej ofte per ili: legante tekston enhavo de
PDFs kaj formanta novan PDFs de ekzistantaj dokumentoj.
La modulo vi uzos por labori kun PDFs estas PyPDF2. Instali ĝin, ruli
pip install PyPDF2 de la komandlinio. Tiu modulo nomo estas usklecodistinga, tiel certigi la y estas minuskla kaj ĉio alia estas majuskle. (Kontrolu Apendico A por plenaj detaloj pri instalado triaj moduloj.) Se la modulo instalis ĝuste, kurante import PyPDF2 en la interaga ŝelo ne montri ajnan eraroj. Ĉerpi Teksto de PDFs
PyPDF2 ne havas manieron ĉerpi bildojn, lertaj, aŭ alispeca de PDF
dokumentoj, sed ĝi povas ĉerpi de teksto kaj reveni ĝin kiel Python
ŝnuro. Komenci lerni kiel PyPDF2 funkcias, ni uzos ĝin en la ekzemplo PDF montrita en Figuro 13-1 .

Figuro 13-1. La PDF paĝon ke ni estos ĉerpi tekston de
Elŝuti tiun ĉi PDF de http://nostarch.com/automatestuff/ kaj eniri la sekva en la interaga konko:
>>> Import PyPDF2 >>> PdfFileObj = malfermita ( 'meetingminutes.pdf', 'rb') >>> PdfReader = PyPDF2.PdfFileReader (pdfFileObj) ❶ >>> pdfReader.numPages 19 ❷ >>> pageObj = pdfReader.getPage (0) ❸ >>> pageObj.extractText () 'OOFFFFIICCIIAALL BBOOAARRDD MMIINNUUTTEESS Kunveno de marto 7, 2015 \ N La Estraro de Elementa kaj Secondary Education devas provizi gvidadon kaj krei politikojn por edukado ke vastigi ŝancojn por infanoj, povigi familioj kaj komunumoj, kaj avancis Luiziano en ĉiufoje konkurenciva tutmonda merkato. ESTRARO de Elementary and Secondary Education '
Unua, importi la
PyPDF2 modulo. Tiam malfermita meetingminutes.pdf en legi duuma reĝimo kaj stoki ĝin en pdfFileObj . Akiri PdfFileReader objekto kiu reprezentas ĉi PDF, voki PyPDF2.PdfFileReader() kaj fordoni pdfFileObj . Stoki ĉi PdfFileReader objekto en pdfReader .
La totala nombro de paĝoj en la dokumento estas stokitaj en la
numPages atributo de PdfFileReader objekto ❶. La ekzemplo PDF havas 19 paĝojn, sed ni ĉerpi tekston de nur la unua paĝo.
Ĉerpi tekston de paĝo, vi bezonas akiri
Page objekto, kiu reprezentas unu retpaĝo de PDF, el PdfFileReader objekto. Vi povas akiri Page objekto nomante la getPage() metodo ❷ sur PdfFileReader objekto kaj pasante ĝin la paĝnumeron de la paĝo vi interesiĝas -en nia kazo, 0.
PyPDF2 uzas nulo-bazita indekso por akiranta paĝoj: La unua paĝo estas paĝo 0, la dua estas Enkonduko kaj tiel plu. Tiu estas ĉiam la kazo, eĉ se paĝojn kalkulon malsame endokumente.
Ekzemple, diru vian PDF estas tri-paĝa eltiraĵo el pli longa raporto,
kaj liaj paĝoj estas numeritaj 42, 43, kaj 44. Por ricevi la unuan paĝon
de ĉi tiu dokumento, vi volus nomi
pdfReader.getPage(0) , ne getPage(42) aŭ getPage(1) .
Unufoje vi havas vian
Page objekto, voki lian extractText() metodon redoni kordo de la paĝo la teksto ❸. La teksto eltiro ne estas perfekta: la teksto Charles E. "Chas" Roemer, Prezidanto de la PDF estas forestanta de la kordo revenis por extractText() , kaj la interspacigo estas foje for. Ankoraŭ, tiu proksimuma kalkulado de la PDF teksto enhavo povas esti sufiĉe bona por via programo. decrypting PDFs
Kelkaj PDF dokumentoj havas ĉifrado karakterizaĵo kiu gardos ilin de
estanta legita ĝis ajn malfermas la dokumento provizas pasvorton. Eniri la sekva en la interaga ŝelo kun la PDF vi elŝutis, kiu estis ĉifrita kun la pasvorton Rosebud:
>>> Import PyPDF2 >>> PdfReader = PyPDF2.PdfFileReader (malfermita ( 'encrypted.pdf', 'rb')) ❶ >>> pdfReader.isEncrypted veraj >>> PdfReader.getPage (0) ❷ Traceback (plej lasta alvoko lasta): Dosiero "<pyshell # 173>", linio 1, en <modulo> pdfReader.getPage () --snip-- Dosiera "C: \ Python34 \ lib \ ejo-pakaĵoj \ PyPDF2 \ pdf.py", linio 1173, en getObject levi utils.PdfReadError ( "dosiero ne estis deĉifrita") PyPDF2.utils.PdfReadError: dosiero ne estis deĉifrita ❸ >>> pdfReader.decrypt ( 'Rosebud') 1 >>> PageObj = pdfReader.getPage (0)
Ĉiuj
PdfFileReader objektoj havas isEncrypted atributo kiu estas True se la PDF estas ĉifrita kaj False se ne ❶. Ajna provo nomi funkcio kiu legas la dosieron antaux gxi estis deĉifrita kun la korekta pasvorton rezultos en eraro ❷.
Legi ĉifrita PDF, invitu
decrypt() funkcio kaj pasi la pasvorton kiel linio ❸. Post vi nomas decrypt() kun la korektan pasvorton, vi vidos ke nomante getPage() ne kaŭzas eraron. Se donita la malĝustan pasvorton, la decrypt() funkcio estos redoni 0 kaj getPage() daŭre malsukcesi. Notu ke la decrypt() metodo deĉifras nur la PdfFileReader objekto, ne la fakta PDF dosieron. Post via programo finiĝas, la dosiero sur via malfacila stirado restas ĉifrita. Via programo devos alvoki decrypt() denove la sekva tempo kuras. krei PDFs
PyPDF2 la contraparte al
PdfFileReader objektoj estas PdfFileWriter objektoj, kiuj povas krei novajn PDF dosierojn. Sed PyPDF2 ne povas skribi arbitra teksto al PDF kiel Python povas fari kun teksto dosierojn.
Anstataŭe, PyPDF2 la PDF-skribo kapabloj estas limigitaj al kopiado
paĝojn el aliaj PDFs, turnanta paĝoj, tavoloj paĝoj, kaj kodi dosierojn.
PyPDF2 ne permesas rekte redakti PDF. Anstataŭe, vi devas krei novan PDF kaj tiam kopii enhavon super el ekzistantan dokumenton. La ekzemploj en ĉi tiu sekcio sekvos tiu ĝenerala aliro:
- Malfermita unu aŭ pli ekzistantaj PDFs (la fonto PDFs) en
PdfFileReaderobjektoj. - Krei novan
PdfFileWriterobjekto. - Kopio paĝoj de la
PdfFileReaderobjektoj en laPdfFileWriterobjekto. - Fine, uzi la
PdfFileWriterobjekto skribi la eligo PDF.
Kreante
PdfFileWriter objekto kreas nur valoro kiu reprezentas dokumento PDF en Python. Ĝi ne kreas la fakta PDF dosieron. Por tio, vi devas alvoki la PdfFileWriter la write() metodon.
La
write() metodo prenas regulan File objekto kiu estis malfermita en skribi-duuma reĝimo. Vi povas akiri tian File objekto nomante Python open() funkcio kun du argumentoj: la ŝnuro de kion vi volas la PDF la dosiernomo esti kaj 'wb' por indiki la dosiero devus esti malfermita en skribi-duuma reĝimo.
Se ĉi sonas iom konfuza, ne maltrankviliĝu-you'll vidos kiel tio funkcias en la jena kodo ekzemploj.
kopiado Paĝoj
Vi povas uzi PyPDF2 kopii paĝoj de unu PDF dokumenton por alia. Tio ebligas vin kombini plurajn PDF dosierojn, tranĉi nedeziratan paĝoj, aŭ reordigi paĝoj.
Elŝutu meetingminutes.pdf kaj meetingminutes2.pdf de http://nostarch.com/automatestuff/ kaj meti la PDFs en la nuna labordosierujon. Eniri la sekva en la interaga konko:
>>> Import PyPDF2 >>> Pdf1File = malfermita ( 'meetingminutes.pdf', 'rb') >>> Pdf2File = malfermita ( 'meetingminutes2.pdf', 'rb') ❶ >>> pdf1Reader = PyPDF2.PdfFileReader (pdf1File) ❷ >>> pdf2Reader = PyPDF2.PdfFileReader (pdf2File) ❸ >>> pdfWriter = PyPDF2.PdfFileWriter () >>> Por pageNum en gamo (pdf1Reader.numPages): ❹ pageObj = pdf1Reader.getPage (pageNum) ❺ pdfWriter.addPage (pageObj) >>> Por pageNum en gamo (pdf2Reader.numPages): ❻ pageObj = pdf2Reader.getPage (pageNum) ❼ pdfWriter.addPage (pageObj) ❽ >>> pdfOutputFile = malfermita ( 'combinedminutes.pdf', 'WB) >>> PdfWriter.write (pdfOutputFile) >>> PdfOutputFile.close () >>> Pdf1File.close () >>> Pdf2File.close ()
Malfermi ambaŭ PDF dosierojn en legi duuma reĝimo kaj stoki la du rezultan
File objektoj en pdf1File kaj pdf2File . Voku PyPDF2.PdfFileReader() kaj fordoni pdf1File akiri PdfFileReader objekto por meetingminutes.pdf ❶. Nomas ĝin denove kaj fordoni pdf2File akiri PdfFileReader objekto por meetingminutes2.pdf ❷. Tiam krei novan PdfFileWriter objekto, kiu reprezentas malplenan dokumento PDF ❸.
Sekva, kopiu ĉiujn paĝojn de la du fonto PDFs kaj aldoni ilin al la
PdfFileWriter objekto. Akiri la Page objekto nomante getPage() sur PdfFileReader objekto ❹. Tiam preterpasonta Page objekto al via PdfFileWriter la addPage() metodo ❺. Tiuj paŝoj estas farita unue por pdf1Reader kaj tiam denove por pdf2Reader . Kiam vi finos kopiante paĝoj, skribi novan PDF nomita combinedminutes.pdf pasante File objekto al la PdfFileWriter la write() metodon ❻. noto
PyPDF2 ne enmeti paĝojn en la mezo de
PdfFileWriter objekto; la addPage() metodo nur aldoni paĝojn al la fino.
Vi nun kreis novan PDF dosieron kiu kombinas la paĝoj de meetingminutes.pdf kaj meetingminutes2.pdf en sola dokumento. Memoru ke la
File objekto pasis al PyPDF2.PdfFileReader() devas esti malfermita en legado duuma reĝimo pasante 'rb' kiel la dua argumento al open() . Simile la File objekto pasis al PyPDF2.PdfFileWriter() devas esti malfermita en skribi-duuma reĝimo kun 'wb' . turnanta Paĝoj
La paĝoj de PDF povas esti turnita en 90-grada pliigoj kun la
rotateClockwise() kaj rotateCounterClockwise() metodoj. Pasas unu el la entjeroj 90 , 180 , aŭ 270 al tiuj metodoj. Eniri la sekva en la interaga ŝelo, kun la meetingminutes.pdf dosieron en la aktuala labordosierujon: >>> Import PyPDF2 >>> MinutesFile = malfermita ( 'meetingminutes.pdf', 'rb') >>> PdfReader = PyPDF2.PdfFileReader (minutesFile) ❶ >>> paĝo = pdfReader.getPage (0) ❷ >>> page.rotateClockwise (90) { '/ Enhavo': [IndirectObject (961, 0), IndirectObject (962, 0), --snip-- } >>> PdfWriter = PyPDF2.PdfFileWriter () >>> PdfWriter.addPage (paĝo) ❸ >>> resultPdfFile = malfermita ( 'rotatedPage.pdf', 'WB) >>> PdfWriter.write (resultPdfFile) >>> ResultPdfFile.close () >>> MinutesFile.close ()
Tie ni uzas
getPage(0) elekti la unuan paĝon de la PDF ❶ kaj tiam ni nomas rotateClockwise(90) en tiu paĝo ❷. Ni skribi novan PDF kun la turnita paĝon kaj savi ĝin kiel rotatedPage.pdf ❸.
La rezultanta PDF havos unu paĝo, rotaciita 90 gradoj dekstrume, kiel en Figuro 13-2 . La reveno valoroj de
rotateClockwise() kaj rotateCounterClockwise() enhavas multan informon ke vi povas ignori. 
Figuro 13-2. La rotatedPage.pdf dosieron kun la paĝon rotaciita 90 gradoj dekstrume
tavoloj Paĝoj
PyPDF2 povas tegi la enhavon de unu paĝon sur alia, kiu estas utila por aldoni logo, tempstampo, aŭ filigrano al paĝo. Kun Python, ĝi estas facile aldoni filigranoj al multnombraj arkivoj kaj nur por paĝoj vian programon specifas.
Elŝutu watermark.pdf de http://nostarch.com/automatestuff/ kaj meti la PDF en la nuna labordosierujon kune kun meetingminutes.pdf. Tiam eniri la sekva en la interaga konko:
>>> Import PyPDF2 >>> MinutesFile = malfermita ( 'meetingminutes.pdf', 'rb') ❷ >>> pdfReader = PyPDF2.PdfFileReader (minutesFile) ❷ >>> minutesFirstPage = pdfReader.getPage (0) ❸ >>> pdfWatermarkReader = PyPDF2.PdfFileReader (malfermita ( 'watermark.pdf', 'rb')) ❹ >>> minutesFirstPage.mergePage (pdfWatermarkReader.getPage (0)) ❺ >>> pdfWriter = PyPDF2.PdfFileWriter () ❻ >>> pdfWriter.addPage (minutesFirstPage) ❼ >>> por pageNum en gamo (1, pdfReader.numPages): pageObj = pdfReader.getPage (pageNum) pdfWriter.addPage (pageObj) >>> ResultPdfFile = malfermita ( 'watermarkedCover.pdf', 'WB) >>> PdfWriter.write (resultPdfFile) >>> MinutesFile.close () >>> ResultPdfFile.close ()
Tie ni faras
PdfFileReader objekto de meetingminutes.pdf ❶. Ni nomas getPage(0) akiri Page objekto por la unua paĝo kaj stoki ĉi objekton en minutesFirstPage ❷. Ni tiam fari PdfFileReader objekto por watermark.pdf ❸ kaj nomas mergePage() sur minutesFirstPage ❹. La argumento ni pasas al mergePage() estas Page objekto por la unua paĝo de watermark.pdf.
Nun ke ni jam nomis
mergePage() sur minutesFirstPage , minutesFirstPage reprezentas la watermarked unua paĝo. Ni faras PdfFileWriter objekto ❺ kaj aldonu watermarked unua paĝo ❻. Tiam ni buklo tra la resto de la paĝoj en meetingminutes.pdf kaj aldoni ilin al la PdfFileWriter objekto ❼. Fine, ni malfermas novajn PDF nomita watermarkedCover.pdf kaj skribi la enhavon de la PdfFileWriter al la novaj PDF.
Figuro 13-3 montras la rezultojn. Nia nova PDF, watermarkedCover.pdf, havas tutan enhavon de la meetingminutes.pdf kaj la unua paĝo estas watermarked.
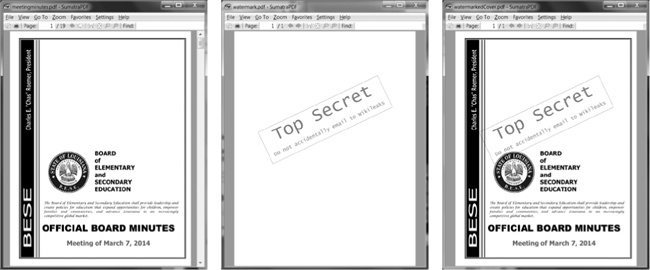
Figuro 13-3. La originala PDF (maldekstre), la filigrano PDF (centro), kaj la kunfandita PDF (dekstra)
kodi PDFs
A
PdfFileWriter objekto povas ankaŭ aldoni ĉifrado al dokumento PDF. Eniri la sekva en la interaga konko: >>> Import PyPDF2 >>> PdfFile = malfermita ( 'meetingminutes.pdf', 'rb') >>> PdfReader = PyPDF2.PdfFileReader (pdfFile) >>> PdfWriter = PyPDF2.PdfFileWriter () >>> Por pageNum en gamo (pdfReader.numPages): pdfWriter.addPage (pdfReader.getPage (pageNum)) ❶ >>> pdfWriter.encrypt ( 'fiŝo glavo) >>> ResultPdf = malfermita ( 'encryptedminutes.pdf', 'WB) >>> PdfWriter.write (resultPdf) >>> ResultPdf.close ()
Antaux nomante la
write() metodon savi al dosiero, nomu la encrypt() metodo kaj fordoni pasvorton ŝnuro ❶. PDFs povas havi uzanto pasvorton (permesante vidi la PDF) kaj posedanto pasvorton (permesante al vi agordi permesojn por presado, komentante, ĉerpante teksto, kaj aliaj ecoj). La uzanto pasvorton kaj mastro pasvorto la unua kaj dua argumentoj por encrypt() , respektive. Se nur unu ĉeno argumento pasis al encrypt() , ĝi estos uzata por ambaŭ pasvortojn.
En ĉi tiu ekzemplo, ni kopiis la paĝoj de meetingminutes.pdf al
PdfFileWriter objekto. Ni ĉifrita la PdfFileWriter kun la pasvorton fiŝo glavo, malfermis novan PDF nomita encryptedminutes.pdf kaj skribis la enhavon de la PdfFileWriter al la novaj PDF. Antaŭ iu ajn povas vidi encryptedminutes.pdf, ili devos eniri tiun pasvorton. Vi eble volas forigi la originalan, neĉifritaj meetingminutes.pdf dosieron post certigante lia kopio estis korekte ĉifrita. Projekto: Kombinante Elektitaj Artikoloj de multaj PDFs
Diru vi havas la enuiga tasko de kunfalado kelkdek PDF dokumentoj en sola PDF-dosiero. Ĉiu el ili havas portita folio kiel la unua paĝo, sed vi ne volas la ferdeko folio ripetita en la fina rezulto. Kvankam estas multaj liberaj programoj por kombini PDFs, multaj el ili simple kunfandi tuta dosierojn kune. Ni skribi Python programo agordi kiun paĝoj vi volas en la kombinita PDF.
Je alta nivelo, jen kion la programo faros:
- Trovu ĉiujn PDF dosierojn en la nuna labordosierujon.
- Ordigi la dosiernomoj tiel la PDFs aldonas en ordo.
- Skribi ĉiun paĝon, ekskludante la unua paĝo, ĉiu PDF al la eligodosiero.En terminoj de efektivigo, via kodo devos fari la sekvan:
- Voku
os.listdir()por trovi ĉiujn dosierojn en la laboranta dosierujo kaj forigi ajnan ne-PDF dosierojn. - Voku Python
sort()listo metodo alfabetizar la dosiernomoj. - Krei
PdfFileWriterobjekto por la eligo PDF. - Buklo super ĉiu PDF-dosiero, kreante
PdfFileReadercelon por ĝi. - Buklo super ĉiu paĝo (krom la unua) en ĉiu PDF-dosiero.
- Aldonu la paĝoj al la eligo PDF.
- Skribi la eligo PDF por dosiero nomata allminutes.pdf.
Por tiu projekto, malfermi novan dosieron redaktanto fenestro kaj savi ĝin kiel combinePdfs.py.
Paŝo 1: Trovu Ĉiuj PDF Dosieroj
Unua, via programo bezonas por ricevi liston de cxiuj dosieroj kun la .pdf etendo en la nuna laboranta dosierujo kaj ordigi ilin. Fari vian kodo aspektas kiel la sekvaj:
#! python3 # CombinePdfs.py - Kombinas ĉiuj PDFs en la nuna labordosierujon en # En ununura PDF. ❶ importado PyPDF2, os # Akiri ĉiuj PDF dosiernomoj. pdfFiles = [] por dosiernomo en os.listdir ( '.'): se filename.endswith ( '. pdf): ❷ pdfFiles.append (dosiernomo) ❸ pdfFiles.sort (ŝlosilo = str.lower) ❹ pdfWriter = PyPDF2.PdfFileWriter () # TODO: Loop tra ĉiuj PDF dosierojn. # TODO: Loop tra ĉiuj paĝoj (krom la unua) kaj aldoni ilin. # TODO: Savu la rezultan PDF al dosiero.
Post la shebang linio kaj la priskriba komentoj pri kio la programo faras, tiu kodo importas la
os kaj PyPDF2 moduloj ❶. La os.listdir('.') Alvoko revenos listo de ĉiu dosiero en la aktuala labordosierujon. La kodo masxojn sur tiu listo kaj aldonas nur tiujn dosierojn kun la .pdf etendo al pdfFiles ❷. Poste, tiu listo estas ordigita laŭ alfabeta ordo kun la key=str.lower ŝlosilvorto argumento por sort() ❸.
A
PdfFileWriter objekto estas kreita por teni la kombinita PDF paĝoj ❹. Fine, kelkaj komentoj skizi la resto de la programo. Paŝo 2: Malfermu Ĉiu PDF
La programo devas legi ĉiun PDF dosiero en
pdfFiles . Aldonu la jenan al via programo: #! python3 # CombinePdfs.py - Kombinas ĉiuj PDFs en la nuna labordosierujon en # Ununura PDF. importado PyPDF2, os # Akiri ĉiuj PDF dosiernomoj. pdfFiles = [] --snip-- # Loop tra ĉiuj PDF dosierojn. por dosiernomo en pdfFiles: pdfFileObj = malfermita (dosiernomo: rb) pdfReader = PyPDF2.PdfFileReader (pdfFileObj) # TODO: Loop tra ĉiuj paĝoj (krom la unua) kaj aldoni ilin. # TODO: Savu la rezultan PDF al dosiero.
Por ĉiu PDF, la buklo malfermas dosiernomo en legado duuma reĝimo nomante
open() kun 'rb' kiel la dua argumento. La open() alvoko redonas File objekto, kiun gets pasis al PyPDF2.PdfFileReader() por krei PdfFileReader objekto por ke PDF- dosieron. Paŝo 3: Aldoni Ĉiu Paĝo
Por ĉiu PDF, vi volas buklo super ĉiu paĝo krom la unua. Aldonu la kodon al via programo:
#! python3 # CombinePdfs.py - Kombinas ĉiuj PDFs en la nuna labordosierujon en # Ununura PDF. importado PyPDF2, os --snip-- # Loop tra ĉiuj PDF dosierojn. por dosiernomo en pdfFiles: --snip-- # Loop tra ĉiuj paĝoj (krom la unua) kaj aldoni ilin. ❶ por pageNum en gamo (1, pdfReader.numPages): pageObj = pdfReader.getPage (pageNum) pdfWriter.addPage (pageObj) # TODO: Savu la rezultan PDF al dosiero.
La kodo ene la
for buklo kopioj ĉiu Page objekto individue al la PdfFileWriter objekto. Memoru, vi volas preterpasi la unua paĝo. Ekde PyPDF2 konsideras 0 esti la unua paĝo, via buklo devus komenci je 1 ❶ kaj tiam iru al, sed ne inkludas, la entjero en pdfReader.numPages . Paŝo 4: Savu la Rezultoj
Post tiuj nestitaj
for cikloj estas farita looping, la pdfWriter variablo enhavos PdfFileWriter objekto kun la paĝojn por ĉiuj PDFs kombinitaj. La lasta paŝo estas skribi ĉi enhavon al dosiero sur la malmola disko. Aldonu la kodon al via programo: #! python3 # CombinePdfs.py - Kombinas ĉiuj PDFs en la nuna labordosierujon en # Ununura PDF. importado PyPDF2, os --snip-- # Loop tra ĉiuj PDF dosierojn. por dosiernomo en pdfFiles: --snip-- # Loop tra ĉiuj paĝoj (krom la unua) kaj aldoni ilin. por pageNum en gamo (1, pdfReader.numPages): --snip-- # Konservu la rezultan PDF al dosiero. pdfOutput = malfermita ( 'allminutes.pdf', 'WB) pdfWriter.write (pdfOutput) pdfOutput.close ()
Pasante
'wb' al open() malfermas la eligo PDF dosiero, allminutes.pdf, en skribi-duuma reĝimo. Tiam, pasante la rezultan File objekto al la write() metodon kreas la fakta PDF dosieron. Voko al la close() metodo finas la programon. Ideoj por Similaj Programoj
Povi krei PDFs de la paĝoj de aliaj PDFs lasos vin fari programojn kiuj povas fari la sekvajn:
- Eltranĉu specifaj paĝoj de PDFs.
- Reordigi paĝoj en PDF.
- Krei PDF de nur tiuj paĝoj kiuj havas iun specifan tekston, identigitaj de
extractText().
vorto Dokumentoj
Python povas krei kaj modifi Vorto dokumentoj, kiujn havas la .DOCX dosiersufikso, kun la
python-docx modulo. Vi povas instali la modulon per kurado pip install python-docx . (Apendico A havas plenan detaloj sur instali triaj moduloj.) noto
Uzinte pip unue instali Python-docx, nepre instali
python-docx , ne docx . La instalado nomo docx estas por malsama modulo ke tiu libro ne kovras. Tamen, Kiam vi estas iranta por importi la python-docx modulo, vi devas kuri import docx , ne import python-docx .
Se vi ne havas Word, LibreOffice Verkisto kaj OpenOffice Writer estas
ambaŭ libera alternativo aplikojn por Windows, OS X, kaj Linukso kiu
povas esti uzata por malfermi .DOCX dosierojn. Vi povas elŝuti ilin de https://www.libreoffice.org kaj http://openoffice.org , respektive. La kompleta dokumentaro por Python-docx disponeblas ĉe https://python-docx.readthedocs.org/ . Kvankam ekzistas versio de Word por OS X, tiu ĉapitro enfokusigos en Word por Windows.
Kompare al ebena teksto, .DOCX dosieroj havas multajn strukturo. Tiu strukturo estas reprezentita per tri malsamaj datumtipoj en Python-docx. Ĉe la plej alta nivelo,
Document objekto reprezentas la tutan dokumenton. La Document objekto enhavas liston de Paragraph celoj por la alineoj en la dokumento. (Nova paragrafo komencas kiam la uzanto premas ENTER aŭ REVENO dum tajpado en Word dokumento.) Ĉiu el tiuj Paragraph objektoj enhavas liston de unu aŭ pli Run objektoj. La sola frazo paragrafo en Figuro 13-4 havas kvar kurojn. 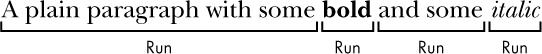
Figuro 13-4. La
Run objektoj identigita en Paragraph objekto
La teksto en Word dokumento estas pli ol nur ŝnuro. Ĝi havas tiparon, grandecon, koloro kaj aliaj stilo informon asociita kun ĝi. Stilo en Word estas kolekto de tiuj atributoj. A
Run objekto estas apuda kuro de teksto kun la sama stilo. Nova Run objekto bezonas ĉiam la tekston stilo ŝanĝoj. Legante Vorto Dokumentoj
Ni sperti kun la
python-docx modulo. Elŝutu demo.docx de http://nostarch.com/automatestuff/ kaj savi la dokumenton al la laboranta dosierujo. Tiam eniri la sekva en la interaga konko: >>> Import docx ❶ >>> doc = docx.Document ( 'demo.docx') ❷ >>> len (doc.paragraphs) 7 ❸ >>> doc.paragraphs [0] .text 'Dokumento Titolo' ❹ >>> doc.paragraphs [1] .text Mallongan ebenaĵo alineo kun iuj aŭdacaj kaj iuj kursiva ' ❺ >>> len (doc.paragraphs [1] .runs) 4 ❻ >>> doc.paragraphs [1] .runs [0] .text Mallongan ebenaĵo alineo kun iu ' ❼ >>> doc.paragraphs [1] .runs [1] .text 'Grasaj' ❽ >>> doc.paragraphs [1] .runs [2] .text 'Kaj iom' ➒ >>> doc.paragraphs [1] .runs [3] .text 'Kursiva'
Ĉe ❶, ni malfermas .DOCX dosieron en Python, voki
docx.Document() , kaj pasi la dosiernomo demo.docx. Tio resendas Document objekto, kiu havas paragraphs atributo kiu estas listo de Paragraph objektoj. Kiam ni vokas len() sur doc.paragraphs , ĝi revenas 7 , kiu diras al ni ke ili estas sep Paragraph objektoj en tiu dokumento ❷. Ĉiu de ĉi tiuj Paragraph objektoj havas text atributo kiu enhavas ŝnuron de la teksto en tiu alineo (sen la stilo informo). Tie, la unua text atributo enhavas 'DocumentTitle' ❸ kaj la dua enhavas 'A plain paragraph with some bold and some italic' ❹.
Ĉiu
Paragraph objekto havas ankaŭ runs atribui tiu estas listo de Run objektoj. Run objektoj ankaŭ havas text atributo, enhavanta nur la teksto en tiu aparta run. Ni rigardu la text atributoj en la dua Paragraph objekto, 'A plain paragraph with some bold and some italic' . Nomante len() sur tiu Paragraph objekto nin diras ke estas kvar Run objektoj ❺. La unua kuro objekto enhavas 'A plain paragraph with some ' ❻. Tiam, la teksto ŝanĝo al aŭdaca stilo, do 'bold' komencas novan Run objekto ❼. La teksto revenas al unbolded stilo post tio, kio rezultas en tria Run objekto, ' and some ' ❽. Fine, la kvara kaj lasta Run objekto enhavas 'italic' en kursiva stilo ➒.
Kun Python-docx, via Python programoj nun povos legi la tekston de .DOCX dosieron kaj uzi ĝin nur kiel ajna alia ĉeno valoro.
Ricevi la Plena Teksto de .DOCX Dosiero
Se vi zorgas nur pri la teksto, ne la stilo informoj, en la Word dokumento, vi povas uzi la
getText() funkcio. Ĝi akceptas dosiernomo de .DOCX dosieron kaj redonas sola kordoj valoro de lia teksto. Malfermi novan dosieron redaktanto fenestro kaj eniri la sekvan kodon, ŝparante ĝin kiel readDocx.py: #! python3 importado docx def gettext (dosiernomo): doc = docx.Document (dosiernomo) plena teksto = [] por para en doc.paragraphs: fullText.append (para.text) reveno '\ n'.join (plena teksto)
La
getText() funkcio malfermas la Vorto dokumenton, loops super ĉiuj Paragraph objektoj en la paragraphs listo, kaj tiam appends sia teksto al la listo en fullText . Post la ciklo, la kordoj en fullText estas ligita kun lino karakteroj.
La readDocx.py programo eblas importitaj kiel ajna alia modulo. Nun se vi nur bezonas la tekston de Word dokumentoj, vi povas eniri la sekvan:
>>> Import readDocx >>> Print (readDocx.getText ( 'demo.docx')) Dokumento Titolo Al ebenaĵo alineo kun iuj aŭdacaj kaj iuj kursivan Rubriko, nivelo 1 intensa citaĵo unua ero en ordigita listo unua ero en ordigita listo
Vi povas ankaŭ adapti
getText() por modifi la ŝnuro antaŭ reveni ĝin. Ekzemple, al krommargxenu ĉiu alineo anstataŭigenda la append() alvoko en readDocx.py kun ĉi: fullText.append ( '' + para.text)
Aldoni duobla spaco en inter paragrafoj, ŝanĝi la
join() alvoko kodon al tiu: reveno '\ n \ n' .join (plena teksto)
Kiel vi povas vidi, ĝi prenas nur kelkajn liniojn de kodo por skribi funkciojn kiuj legos .DOCX dosiero returne kordo de ĝia enhavo laŭplaĉe.
Stilo Paragrafo kaj Run Objektoj
En Word por Windows, vi povas vidi la stiloj premante CTRL - ALT - klavoj MAJUSKLIGA -s montri la Stiloj panelo, kiu aspektas kiel Figuro 13-5 . Sur OS X, vi povas vidi la Stiloj panelo klakante la Vidi ▸ Stiloj menuero.
Figuro 13-5. Montri la Stiloj panelo premante
CTRL-ALT-SHIFT -s en Windows.
Vorto kaj aliaj dokumentoredaktiloj uzu stilojn teni la vida prezento de similaj tipoj de teksto konsekvenca kaj facile ŝanĝi. Ekzemple, eble vi volas agordi korpo alineoj en 11-punkta, Times New Roman, maldekstra-pravigita, ĉifona dekstra tekston. Kreu stilo kun tiuj difinoj kaj atribui al ĉiu korpo alineoj.
Tiam, se vi poste volas ŝanĝi la prezenton de ĉiuj korpo paragrafoj en
la dokumenton, vi povas simple ŝanĝi la stilon, kaj ĉiuj tiuj alineoj
estas aŭtomate ĝisdatigita.
Por Word dokumentoj, estas tri tipoj de stiloj: Paragrafo stiloj povas esti aplikita al
Paragraph objektoj, karaktero stiloj povas esti aplikita al Run objektoj, kaj ligitaj stiloj povas esti aplikita al ambaŭ specoj de celoj. Vi povas doni ambaŭ Paragraph kaj Run objektoj stiloj de fiksanta ilian style atributo al ĉeno. Tiu ŝnuro devus esti la nomo de stilo. Se style estas agordita None do ne estos stilo asociita kun la Paragraph aŭ Run objekto.
La kordoj valoroj por la defaŭlta Vorto stiloj estas kiel sekvas:
'Normal' | 'Heading5' | 'ListBullet' | 'ListParagraph' |
'BodyText' | 'Heading6' | 'ListBullet2' | 'MacroText' |
'BodyText2' | 'Heading7' | 'ListBullet3' | 'NoSpacing' |
'BodyText3' | 'Heading8' | 'ListContinue' | 'Quote' |
'Caption' | 'Heading9' | 'ListContinue2' | 'Subtitle' |
'Heading1' | 'IntenseQuote' | 'ListContinue3' | 'TOCHeading' |
'Heading2' | 'List' | 'ListNumber' | 'Title' |
'Heading3' | 'List2' | 'ListNumber2' | |
'Heading4' | 'List3' | 'ListNumber3' |
Kiam fiksante la
style atributo, ne uzu spacojn en la stilo nomo. Ekzemple, dum la stilo nomo estu Subtila Emfazo, vi devus agordi la style atributo al la kordo valoro 'SubtleEmphasis' anstataŭ 'Subtle Emphasis' . Inkluzive spacojn kaŭzos vorto mislegis la stilo nomo kaj ne apliki ĝin.
Uzinte kunligita stilo por
Run objekto, vi bezonos aldoni 'Char' al la fino de lia nomo. Ekzemple, agordi la Citaĵo ligitaj stilo por Paragraph objekto, vi uzus paragraphObj.style = 'Quote' , sed por Run objekto, vi uzus runObj.style = 'QuoteChar' .
En la nuna versio de Python-docx (0.7.4), la sola stiloj kiuj povas
esti uzitaj estas la defaŭlta Vorto stiloj kaj stiloj en la malfermita .DOCX. Novaj stiloj povas ne esti kreitaj-kvankam tio povas ŝanĝi en futuraj versioj de Pitono-docx.
Kreanta Vorto Dokumentoj kun Nondefault Stiloj
Se vi volas krei Vorto dokumentoj kiuj uzas stiloj trans defaŭltojn, Vi
bezonas malfermi vorto malplenan Vorto dokumenton kaj krei la stilojn
mem klakante la New Style butono ĉe la fundo de la Stiloj panelo ( Figuro 13-6 spektakloj tio sur Vindozo).
Tio malfermas la Create New Style de Formatado dialogon, kie vi povas eniri la novan stilon. Do reiru al la interaga ŝelo kaj malfermu tiun malplenan Vorto dokumenton kun
docx.Document() , uzi ĝin kiel la bazo por via Word dokumento. La nomo vi donis tiun stilon nun estos disponebla por uzi kun Python-docx. 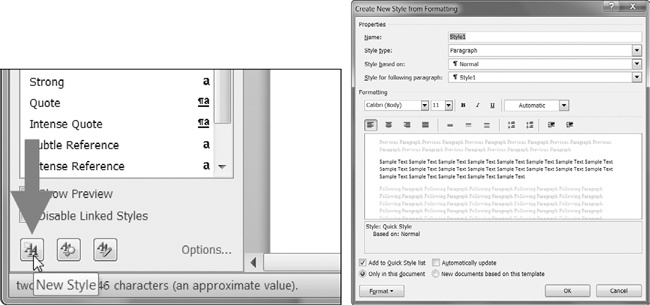
Figuro 13-6. La Nova Stilo butono (maldekstre) kaj la Create New Style de formatado dialogo (dekstre)
kuri Atributoj
Runs povas plui stiligas uzante
text atributoj. Ĉiu atributo povas esti aro al unu el tri valoroj: True (la atributo estas ĉiam ŝaltita, negrave kia alia stiloj aplikas al la kuron), False (la atributo estas ĉiam handikapita), aŭ None (defaŭltoj al kiom la kuro stilo estas aro).
Tabelo 13-1 listigas la
text atributoj kiuj povas stari sur Run objektoj.
Tabelo 13-1.
Run Objekto text Atributoj
atributo
|
priskribo
|
|---|---|
bold |
La teksto aperas en grasa skribo.
|
italic |
La teksto aperas kursive.
|
underline |
La teksto estas substrekita.
|
strike |
La teksto aperas kun forstrekita.
|
double_strike |
La teksto aperas kun duobla forstrekita.
|
all_caps |
La teksto aperas en majuskloj.
|
small_caps |
La teksto aperas en majuskloj, kun minuskla literoj du punktoj pli malgrandaj.
|
shadow |
La teksto aperas kun ombro.
|
outline |
La teksto aperas skizita anstataŭ solida.
|
rtl |
La teksto estas skribita dekstra-al-maldekstra.
|
imprint |
La teksto aperas premita en la paĝo.
|
emboss |
La teksto aperas levita for la paĝon en reliefo.
|
Ekzemple, ŝanĝi la stilojn de demo.docx, eniri la sekva en la interaga konko:
>>> Doc = docx.Document ( 'demo.docx') >>> Doc.paragraphs [0] .text 'Dokumento Titolo' >>> Doc.paragraphs [0] .style 'Titolo' >>> Doc.paragraphs [0] .style = 'Normala' >>> Doc.paragraphs [1] .text Mallongan ebenaĵo alineo kun iuj aŭdacaj kaj iuj kursiva ' >>> (Doc.paragraphs [1] .runs [0] .text, doc.paragraphs [1] .runs [1] .text, doc. alineoj [1] .runs [2] .text, doc.paragraphs [1] .runs [3] .text) ( 'A ebenaĵo alineo kun iu', 'grasaj' 'kaj iu', 'kursiva') >>> Doc.paragraphs [1] .runs [0] .style = 'QuoteChar' >>> doc.paragraphs [1] .runs [1] .underline = Vera >>> doc.paragraphs [1] .runs [ 3] .underline = Vera >>> doc.save ( 'restyled.docx')
Tie, ni uzas la
textkaj styleatributoj facile vidi kio estas en la paragrafoj en nia dokumenton. Ni povas vidi ke ĝi estas simpla dividi alineon en kuroj kaj aliri ĉiu run individiaully. Tiel ni atingos la unua, dua kaj kvara kurojn en la dua alineo, stilo ĉiu kuro, kaj savi la rezultojn al nova dokumento.
Vortoj Dokumento Titolo en la supro de restyled.docx havos la Normala stilo anstataŭ la Titolo stilo, la
Runobjekto de la teksto A ebenaĵo alineo kun iu havos la QuoteChar stilo, kaj la du Runceloj por la vortoj aŭdaca kaj kursivan havos iliajn underlineecojn metita True. Figuro 13-7 montras kiel la stiloj de alineoj kaj kuroj enrigardi restyled.docx .
Figuro 13-7. La restyled.docx dosieron
Vi povas trovi pli kompletan dokumentaron pri Python-docx uzo de stiloj en https://python-docx.readthedocs.org/en/latest/user/styles.html .
Skribi Vorto Dokumentoj
Eniri la sekva en la interaga konko:
>>> Import docx >>> doc = docx.Document () >>> doc.add_paragraph ( 'Saluton mondo!') <Docx.text.Paragraph objekto ĉe 0x0000000003B56F60> >>> Doc.save ( 'helloworld.docx')
Krei vian propran .DOCX dosiero, nomu
docx.Document()al reveni novan, malplenan Vorto Documentobjekto. La add_paragraph()dokumenton metodo aldonas novan alineon de teksto al la dokumento kaj redonas referencon al la Paragraphobjekto kiu estis aldonita. Kiam vi finos aldonante teksto, pasi dosiernomo ŝnuro al la save()dokumenton metodo por savi la Documentobjekto al dosiero.
Tio kreos dosieron nomita helloworld.docx en la nuna labordosierujon ke, kiam malfermiĝis, aspektas kiel Figuro 13-8 .
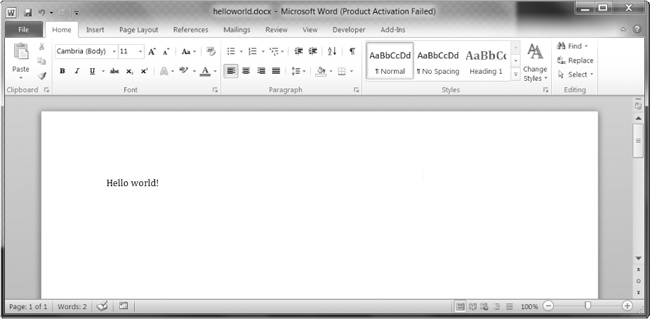
Figuro 13-8. La Vorto dokumenton kreita uzante
add_paragraph('Hello world!')
Vi povas aldoni alineojn nomante la
add_paragraph()metodo denove kun la nova alineo de teksto. Aŭ aldoni tekston al la fino de ekzistanta alineo, vi povas nomi la alineo la add_run()metodo kaj fordoni kordo. Eniri la sekva en la interaga konko: >>> Import docx >>> doc = docx.Document () >>> doc.add_paragraph ( 'Saluton mondo!') <Docx.text.Paragraph objekto ĉe 0x000000000366AD30> >>> ParaObj1 = doc.add_paragraph ( 'Jen dua alineo.') >>> ParaObj2 = doc.add_paragraph ( 'Jen alia alineo.') >>> ParaObj1.add_run ( 'Tiu teksto estas aldonita al la dua alineo.) <Docx.text.Run objekto ĉe 0x0000000003A2C860> >>> Doc.save ( 'multipleParagraphs.docx')
La rezultanta dokumenton similos Figuro 13-9 . Notu ke la teksto Tiu teksto estas aldonita al la dua alineo. Estis aldonita al la
Paragraphobjekto en paraObj1kiu estis la dua paragrafo aldonita al doc. La add_paragraph()kaj add_run()funkcioj reveni paragrafo kaj Runobjektoj, respektive, por savi vin la penon ĉerpi ilin kiel aparta paŝo.
Memoru ke de Python-docx versio 0.5.3, novaj
Paragraphobjektoj povas esti aldonita nur al la fino de la dokumento, kaj novaj Runobjektoj povas esti aldonita nur al la fino de Paragraphobjekto.
La
save()metodo povas esti nomata denove savi la kromajn ŝanĝojn vi faris.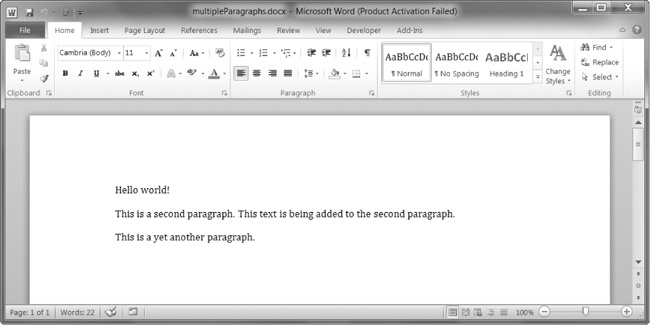
Figuro 13-9. La dokumenton kun multnombraj
Paragraphkaj Runobjektoj aldonitaj
Ambaŭ
add_paragraph()kaj add_run()akceptas laŭvolan duan argumenton ke estas ĉeno de la Paragraphaŭ Runobjekto stilo. Ekzemple:>>> Doc.add_paragraph ( 'Saluton mondo!', 'Titolo')
Tiu linio aldonas alineon kun la teksto Saluton mondo! En la Titolo stilo.
aldonante Rubrikoj
Voko
add_heading()aldonas alineon kun unu el la rubriko stiloj. Eniri la sekva en la interaga konko: >>> Doc = docx.Document () >>> doc.add_heading ( 'Kapa 0', 0) <Docx.text.Paragraph objekto ĉe 0x00000000036CB3C8> >>> Doc.add_heading ( 'Kapa 1', 1) <Docx.text.Paragraph objekto ĉe 0x00000000036CB630> >>> Doc.add_heading ( 'Kapa 2', 2) <Docx.text.Paragraph objekto ĉe 0x00000000036CB828> >>> Doc.add_heading ( 'Kapa 3', 3) <Docx.text.Paragraph objekto ĉe 0x00000000036CB2E8> >>> Doc.add_heading ( 'Kapa 4', 4) <Docx.text.Paragraph objekto ĉe 0x00000000036CB3C8> >>> Doc.save ( 'headings.docx')
La argumentoj por
add_heading()estas ŝnuro de la rubriko teksto kaj entjero el 0al 4. La entjero 0faras la rubriko la Titolo stilo, kiu estas uzata por la supro de la dokumento. Entjeroj 1al 4estas por diversaj rubriko niveloj, kun 1estante la ĉefa rubriko kaj 4la plej malalta subheading. La add_heading()funkcio redonas Paragraphcelon savi vin la paŝo de ĉerpi ĝin el la Documentobjekto kiel aparta paŝo.
La rezultanta headings.docx dosiero aspektos kiel Figuro 13-10 .

Figuro 13-10. La headings.docx dokumenton kun rubrikoj 0 ĝis 4
Aldonante Linio kaj Paĝo Breaks
Aldoni linerompo (prefere ol komenci tute novan alineon), vi povas nomi la
add_break()metodon sur la Runobjekto vi deziras havi la paŭzo aperos poste. Se vi volas aldoni paĝo paŭzo anstataŭe, vi devas pasi la valoron docx.text.WD_BREAK.PAGEkiel sola argumento add_break(), kiel oni faras en la mezo de la sekvanta ekzemplo:>>> Doc = docx.Document () >>> doc.add_paragraph ( 'tio estas en la unua paĝo!) <Docx.text.Paragraph objekto ĉe 0x0000000003785518> ❶ >>> doc.paragraphs [0] .runs [0] .add_break (docx.text.WD_BREAK.PAGE) >>> doc.add_paragraph ( 'tio estas sur la dua paĝo!) <Docx.text.Paragraph objekto ĉe 0x00000000037855F8> >>> Doc.save ( 'twoPage.docx')
Tio kreas du-paĝa Vorto dokumenton kun tiu estas en la unua paĝo! Sur la unua paĝo kaj tiu estas sur la dua paĝo! Sur la dua. Kvankam ekzistis daŭre multe da spaco sur la unua paĝo, post la teksto tio estas en la unua paĝo! , Ni pelis la sekva alineo komenci en nova paĝo de enmeto paĝo paŭzo post la unua kuro de la unua alineo ❶.
aldonante Bildoj
Documentobjektoj havas add_picture()metodon kiu lasos vin aldoni bildon al la fino de la dokumento. Diru vi havas dosieron zophie.png en la nuna labordosierujon. Vi povas aldoni zophie.png
al la fino de via dokumento kun larĝa de 1 colo kaj alteco de 4
centimetroj (Vorto povas uzi ambaŭ imperiaj kaj metrikaj unuoj)
enmetante la sekvaj:>>> Doc.add_picture ( 'zophie.png', larĝeco = docx.shared.Inches (1), alteco = docx.shared.Cm (4)) <docx.shape.InlineShape objekto ĉe 0x00000000036C7D30>
La unua argumento estas ĉeno de la statuo dosiernomo. La laŭvola
widthkaj heightŝlosilvorto argumentoj starigos la larĝeco kaj alteco de la bildo en la dokumento. Se preterlasitaj, la larĝeco kaj alteco default al la normala grandeco de la bildo.
Vi probable preferas specifi bildon la alteco kaj larĝeco en familiara unuoj kiaj coloj kaj centimetroj, do vi povas uzi la
docx.shared.Inches()kaj docx.shared.Cm()funkcioj kiam vi preciziganta la widthkaj heightŝlosilvorto argumentoj.resumo
Teksto informo ne nur por teksto dosierojn; fakte, estas sufiĉe probabla kiu vin traktas PDFs kaj Word dokumentoj multe pli ofte. Vi povas uzi la
PyPDF2modulon por legi kaj skribi PDF dokumentoj. Bedaŭrinde,
legante tekston de PDF dokumentoj eble ne ĉiam rezultos en perfekta
traduko al ĉeno pro la komplika PDF dosiero formato, kaj iuj PDFs povus
ne esti legebla ajn. En tiuj kazoj, vi estas el sorton krom se estontaj ĝisdatigoj al PyPDF2 apogi kromajn PDF karakterizaĵoj.
Vorto dokumentoj estas pli fidinda, kaj vi povas legi ilin per la
python-docxmodulo. Vi povas manipuli tekston en Word dokumentoj tra Paragraphkaj Runobjektoj. Tiuj celoj povas ankaŭ esti donita stiloj, kvankam ili devas esti de la defaŭlta aro de stiloj aŭ stiloj jam en la dokumento. Vi povas aldoni novajn paragrafojn, rubrikoj, paŭzoj kaj fotojn al la dokumento, kvankam nur al la fino.
Multaj
de la limigoj kiuj venas kun laborante kun PDFs kaj Word dokumentoj ĉar
tiuj formatoj estas signifita esti bele montrata por homaj legantoj,
anstataŭ facile analizi por programaro. La sekva ĉapitro prenas rigardi du aliaj komunaj formatoj por stoki informon: JSON kaj CSV dosierojn. Tiuj
formatoj estas desegnitaj por esti uzita per komputiloj, kaj vi vidos
ke Python povas labori kun tiuj formatoj multe pli facile.
praktiko Demandoj
Q:
|
1. Kordo valoro de la PDF dosiernomo ne pasis al la
PyPDF2.PdfFileReader()funkcio. Kion vi pasas al la funkcio anstataŭe? |
Q:
|
2. Kio modaloj ĉu la
Fileceloj por PdfFileReader()kaj PdfFileWriter()devas esti malfermita en? |
Q:
| |
Q:
|
4. Kio
PdfFileReadervariablo tendencas la nombro de paĝoj en la dokumento PDF? |
Q:
|
5. Se
PdfFileReaderobjekto PDF estas ĉifrita kun la pasvorton swordfish, kion vi devas fari antaŭ ol vi povas akiri Pagecelojn de gxi? |
Q:
|
6. Kio metodoj vi uzas por turni paĝo?
|
Q:
|
7. Kio metodo redonas
Documentcelon por dosiero nomata demo.docx ? |
Q:
|
8. Kio estas la diferenco inter
Paragraphobjekto kaj Runcelon? |
Q:
|
9. Kiel vi akiri liston de
Paragraphobjektoj por Documentobjekto kiun oni stokitaj en variablo nomata doc? |
Q:
|
10. Kio tipo de objekto havas
bold, underline, italic, strike, kaj outlinevariabloj? |
Q:
|
11. Kio estas la diferenco inter opcio la
boldvariablo al True, Falseaŭ None? |
Q:
|
12. Kiel vi kreas
Documentobjekton por nova Vorto dokumenton? |
Q:
|
13. Kiel vi aldoni alineon kun la teksto
'Hello there!'al Documentobjekto stokitaj en variablo nomata doc? |
Q:
|
14. Kio entjeroj reprezentas la nivelojn de titoloj disponeblaj en Word dokumentoj?
|
praktiko Projektoj
Por praktiko, skribi programojn kiuj faras la sekvan.
PDF Paranojo
Uzante la
os.walk()funkcion de Ĉapitro 9
, skribi skripto kiu trairos ĉiun PDF en dosierujo (kaj ĝia
subdosierujojn) kaj ĉifri la PDFs uzanta pasvorto provizita per la
komandlinio. Savu ĉiu ĉifrita PDF kun _encrypted.pdf sufikso aldonita al la originala dosiernomo. Antaŭ
ol forigi la originalan dosieron, havas la programon provo legi kaj
deĉifri la dosieron por certigi ke ĝi estis ĉifrita korekte.
Tiam,
skribi programon kiu trovas ĉiu ĉifrita PDFs en dosierujo (kaj ĝia
subdosierujojn) kaj kreas deĉifrita kopion de la PDF uzante provizita
pasvorton. Se la pasvorto estas malĝusta, la programo devus presi mesaĝon al la uzanto kaj daŭrigi al la venonta PDF.
Kutimo Invitoj kiel Word Dokumentoj
Diru vi havas tekstdosiero de gasto nomoj. Ĉi guests.txt dosiero havas nomon por linio, jene:
Profesoro Pruno Miss Scarlet Kolonelo mustardo Al Sweigart Robocop
Skribi programon kiu generus Vorto dokumenton kun kutimo invitoj kiuj aspektas kiel Figuro 13-11 .
Ekde
Python-docx povas uzi nur tiuj stiloj kiuj jam ekzistas en la Vorto
dokumento, vi devos unua aldoni tiujn stilojn al malplenan Vorto dosiero
kaj poste malfermi tiu dosiero kun Python-docx. Tie devus esti unu invito por paĝo en la rezulta Vorto dokumento, do nomu
add_break()aldoni paĝo paŭzo post la lasta alineo de ĉiu invito. Tiel, vi bezonas malfermi nur unu Vorto dokumenton presi ĉio el la invitoj samtempe.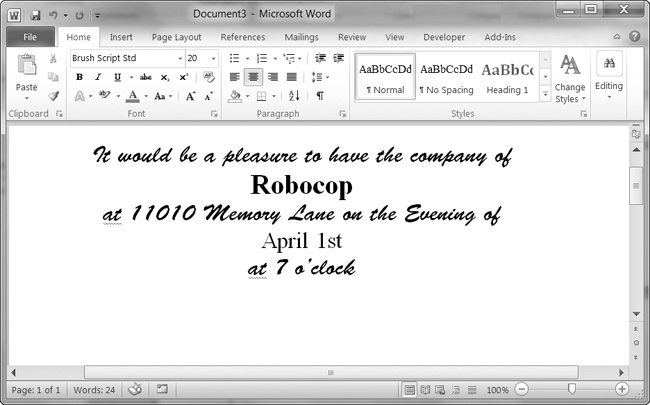
Figuro 13-11. La Vorto dokumenton generita per via kutimo inviti skripto
Vi povas elŝuti specimeno guests.txt dosiero de http://nostarch.com/automatestuff/ .
Malpura Forto PDF Pasvorto Breaker
Diru vi havas ĉifrita PDF ke vi forgesis la pasvorton al, sed vi memoru estis sola angla vorto. Provas diveni viajn forgesis pasvorton estas sufiĉe enuiga tasko. Anstataŭe vi povas skribi programon kiu malĉifri la PDF provante ĉiu ebla Esperanta vorto ĝis ĝi trovas unu kiu funkcias. Tiu estas nomata kiel malpura forto pasvorton atako. Elŝutu la tekstdosiero dictionary.txt de http://nostarch.com/automatestuff/ . Ĉi vortaro dosieron enhavas super 44,000 anglaj vortoj kun unu vorto por linio.
Uzante la dosiero-leganta kapablojn vi lernis en Ĉapitro 8 , krei liston de vorto kordoj legante tiun dosieron. Tiam buklo super ĉiu vorto en tiu listo, pasante ĝin al la
decrypt()telefono. Se tiu metodo revenas la entjero 0, la pasvorto estis erara kaj via programo devus daŭrigi al la venonta pasvorton. Se decrypt()revenas 1, tiam via programo devus rompi la buklo kaj presi la Hakita pasvorton. Vi devus provi ambaŭ la majuskla kaj minusklaj formo de ĉiu vorto. (Sur
mia tekkomputilo, irante tra ĉiu 88.000 majusklajn kaj minuskla vortoj
de la vortaro dosiero prenas paron de minutoj. Jen kial vi ne uzas
simplan angla vorto por viaj pasvortoj.)
Nenhum comentário:
Postar um comentário